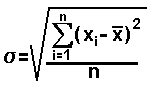
| Label | Data Set |
| A | {72, 72, 73, 73, 105, 105, 105, 110, 110, 111, 111, 112, 112, 113, 116} |
| B | {5, 5, 6, 105, 105, 105, 109, 110, 125, 125, 130, 135, 140, 145, 150} |
| C | {-710, -706, -704, -700, 80, 105, 105, 110, 557, 558, 559, 560, 561, 562, 563} |
| D | {-2510, -106, -105, -100, 80, 105, 105, 110, 207, 208, 209, 210, 211, 212, 2664} |
| E | {80, 81.6, 81.7, 81.9, 82, 105, 105, 110, 110.1, 110.2, 110.3, 110.4, 110.5, 110.6, 110.7} |
| F | {-710, 80, 94, 96, 100, 105, 105, 110, 157, 158, 159, 160, 161, 162, 563} |
| G | {-710, 60, 74, 76, 100, 105, 105, 110, 111, 112, 113, 114, 222, 345, 563} |
The mean, median, and mode values of these seven data sets are fixed, and yet the data values in the sets are clearly different. Measures of central tendency characterize the "center" of the data but they do not give us any information about the "spread" of that data. Characterizing the "spread" of the data values is the task of the measures of dispersion, the range, the quartile points, and the standard deviation. The following table gives the values for these measures for each of the data sets given above.
| Label | Data Set | Range | First Quartile | Second Quartile |
Third Quartile | Standard Deviation |
| A | {72, 72, 73, 73, 105, 105, 105, 110, 110, 111, 111, 112, 112, 113, 116} | 72 to 116 | 73 | 110 | 112 | 16.844 |
| B | {5, 5, 6, 105, 105, 105, 109, 110, 125, 125, 130, 135, 140, 145, 150} | 5 to 150 | 105 | 110 | 135 | 49.425 |
| C | {-710, -706, -704, -700, 80, 105, 105, 110, 557, 558, 559, 560, 561, 562, 563} | -710 to 563 | -700 | 110 | 560 | 521.148 |
| D | {-2510, -106, -105, -100, 80, 105, 105, 110, 207, 208, 209, 210, 211, 212, 2664} | -2510 to 2664 | -100 | 110 | 210 | 951.601 |
| E | {80, 81.6, 81.7, 81.9, 82, 105, 105, 110, 110.1, 110.2, 110.3, 110.4, 110.5, 110.6, 110.7} | 80 to 110.7 | 81.9 | 110 | 110.4 | 13.248 |
| F | {-710, 80, 94, 96, 100, 105, 105, 110, 157, 158, 159, 160, 161, 162, 563} | -710 to 563 | 96 | 110 | 160 | 243.903 |
| G | {-710, 60, 74, 76, 100, 105, 105, 110, 111, 112, 113, 114, 222, 345, 563} | -710 to 563 | 76 | 110 | 114 | 251.530 |
Once we know the range, we at least know the boundaries of the data. The following table reproduces the data set Labels and the range values given above.
| Label | Range |
| A | 72 to 116 |
| B | -5 to 150 |
| C | -710 to 563 |
| D | -2510 to 2664 |
| E | 80 to 110.7 |
| F | -710 to 563 |
| G | -710 to 563 |
Just looking at the range values in the table, without seeing the original data sets, we now have a feel for the spread of the values in each data set. We know that all seven data sets have a mean of 100 and a median of 110. Knowing the range immediately tells us that data set D has some extreme values, whereas data sets A and E stay fairly close to the mean and the median.
Although the range gives the extreme values (the minimum and maximum) in the data set, we cannot tell if there is only one extreme value or if many of the values are spread out. In the example above, data sets C, F, and G have the identical range, namely, -710 to 563. They also have the same mean, median, and mode. Just knowing the values of the measures of central tendency and knowing the range does not distinguish between the three data sets. And yet, data sets C, F, and G are quite different. Data set C has a cluster of 4 values that are very low (around -700), a cluster of 4 values in the middle (around 105), and a cluster of 7 high values (around 560). Data set F has just one low value (-710), 13 values spread between 80 and 162, and one high value (563). And, data set G has one low value (-710), 11 middle values from 60 to 114, and then three higher values (222, 345, and 563). The range is not giving us enough information to get a feel for the differences in these data sets without looking at the actual values.
Return to the three data sets, C, F, and G, and examine their quartile points in the table below.
| Label | Data Set | 25% | 50% | 75% |
| C | {-710, -706, -704, -700, 80, 105, 105, 110, 557, 558, 559, 560, 561, 562, 563} | -700 | 110 | 560 |
| F | {-710, 80, 94, 96, 100, 105, 105, 110, 157, 158, 159, 160, 161, 162, 563} | 96 | 110 | 160 |
| G | {-710, 60, 74, 76, 100, 105, 105, 110, 111, 112, 113, 114, 222, 345, 563} | 76 | 110 | 114 |
We see the difference in the data sets reflected in the quartile points.
It should be noted that the quartile points, the first, second, and third quartile points, form a nice bridge across the data values. We extend that bridge to the extremes of the data values by adding the range values as the zeroeth and fourth quartile points. Thus, the full table of quartile points would be:
| Label | Data Set | 0th Quartile 0% |
1st Quartile 25% | 2nd Quartile 50% |
3rd Quartile 75% | 4th Quartile 100% |
| C | {-710, -706, -704, -700, 80, 105, 105, 110, 557, 558, 559, 560, 561, 562, 563} | -710 | -700 | 110 | 560 | 563 |
| F | {-710, 80, 94, 96, 100, 105, 105, 110, 157, 158, 159, 160, 161, 162, 563} | -710 | 96 | 110 | 160 | 563 |
| G | {-710, 60, 74, 76, 100, 105, 105, 110, 111, 112, 113, 114, 222, 345, 563} | -710 | 76 | 110 | 114 | 563 |
The concept of quartiles works quite well. It gives us a feel for the distribution of values within the data set. It is tempting to extend the concept from 4 quarters to 10 equal parts, thus obtaining the 10%, 20%, 30%, 40%, and so on points. This would be silly for the 15 values in the example data that we are using above. It would make more sense if the data set had hundreds of values in it. The difficulty with this approach, having more and more marker points, is that it is harder and harder to look at all of the marker points and make some sense out of them. Therefore, we generally stay with quartile points.
Thus far we have merely stated that the standard deviation exists and that it is applicable to interval and ratio measurements. We have not presented a way to compute the standard deviation. The formula for the standard deviation is quite complex. It is generally given as
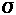 , the symbol for standard deviation.
The definition states that is equal
to the square root of a quantity. That quantity is the quotient of
, the symbol for standard deviation.
The definition states that is equal
to the square root of a quantity. That quantity is the quotient of
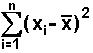 and
, is another
mathematical expression. It represents
the sum of many terms.
The
and
, is another
mathematical expression. It represents
the sum of many terms.
The 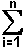 tells us to "obtain the sum of every term, specified by the expression that follows the symbol,
for each value of i from 1 to n".
We have n values in the data set, and this represents the sum of one term
for each value in the data set. The individual terms are given as
.
We divide that sum by the number of items,
tells us to "obtain the sum of every term, specified by the expression that follows the symbol,
for each value of i from 1 to n".
We have n values in the data set, and this represents the sum of one term
for each value in the data set. The individual terms are given as
.
We divide that sum by the number of items, The following table presents the values used in the calculation of the standard deviation for data set A as given above.
| i | xi | xi-x | (xi-x)2 | |
| 1 | 72 | -28 | 784 | |
| 2 | 72 | -28 | 784 | |
| 3 | 73 | -27 | 729 | |
| 4 | 73 | -27 | 729 | |
| 5 | 105 | 5 | 25 | |
| 6 | 105 | 5 | 25 | |
| 7 | 105 | 5 | 25 | |
| 8 | 110 | 10 | 100 | |
| 9 | 110 | 10 | 100 | |
| 10 | 111 | 11 | 121 | |
| 11 | 111 | 11 | 121 | |
| 12 | 112 | 12 | 144 | |
| 13 | 112 | 12 | 144 | |
| 14 | 113 | 13 | 169 | |
| 15 | 116 | 16 | 256 | |
| sum= | 1500 | 4256 | ||
| sum/15= | 100 | 283.7333 | ||
| square root= | 16.84439 | |||
This may seem to be a messy, complex, solution, and it is. Fortunately, there is another formula for calculating the standard deviation. This is an equivalent formula, but unlike the one given above, the new formula does not require you to find the mean before you complete the other actions. The alternative formula is
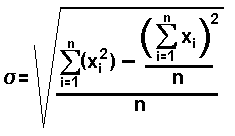
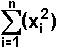 , which represents the sum of the squares of
each of the data values. The second instance is
, which represents the sum of the squares of
each of the data values. The second instance is
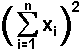 ,
which represents finding the sum of all the data values and then squaring that sum.
This formula is easier to compute because as we go through the data values we need only compute the sum of
the data values and the sum of the squares of the data values. Once that is done, then
we can compute the standard deviation as given in the second version.
Below is a table of the data values from set A and their squares, along with the sum of each.
,
which represents finding the sum of all the data values and then squaring that sum.
This formula is easier to compute because as we go through the data values we need only compute the sum of
the data values and the sum of the squares of the data values. Once that is done, then
we can compute the standard deviation as given in the second version.
Below is a table of the data values from set A and their squares, along with the sum of each.
| i | xi | xi2 | |
| 1 | 72 | 5184 | |
| 2 | 72 | 5184 | |
| 3 | 73 | 5329 | |
| 4 | 73 | 5329 | |
| 5 | 105 | 11025 | |
| 6 | 105 | 11025 | |
| 7 | 105 | 11025 | |
| 8 | 110 | 12100 | |
| 9 | 110 | 12100 | |
| 10 | 111 | 12321 | |
| 11 | 111 | 12321 | |
| 12 | 112 | 12544 | |
| 13 | 112 | 12544 | |
| 14 | 113 | 12769 | |
| 15 | 116 | 13456 | |
| sum of xi= | 1500 | sum of xi2= | 154256 |
is 15002=2250000, and that value divided by 15 is 150000.
The sum of the squared values,
,
is 154256, and the difference between 154256
and 150000 is 4256. Then we divide that value by 15 to get 283.73333,
to which we apply the square root operation to get a final answer of 16.844, as we
computed using the first formula.
As fortunate as it is to have the alternative formula, even more fortunate is the fact that most scientific and all graphing calculators do all of this work for us. The following table gives the screen images and an explanation for obtaining the standard deviation, and other values, on a TI-86 (a demonstration of the TI-83 follows below).
|
Figure 1 shows the statement used to create a list, called A, which contains the
values in our data set. Note that the calculator started with a clear screen,
  ,
and that we used the ,
and that we used the
 and and  keys to select the { and the }
from that menu. The comma was generated via the keys to select the { and the }
from that menu. The comma was generated via the  key.
The "store" symbol, key.
The "store" symbol,  key. That key put the calculator into alphabetic mode. As a result,
the A was generated by pressing the key. That key put the calculator into alphabetic mode. As a result,
the A was generated by pressing the  key. key.
|
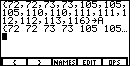
| Figure 2 is a result of pressing the  key
to perform the command given in Figure 1. key
to perform the command given in Figure 1. |
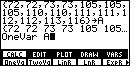
| The goal of Figure 3 is to generate the statement OneVar A.
To do this on the TI-86 (the TI-85 is quite different) we open the STAT menu via
 and then open the
CALC submenu via the key. Our desired command is in the first
option poisition, so we press to paste "OneVar " onto the screen.
We complete the statement via the keys to generate the final
A. and then open the
CALC submenu via the key. Our desired command is in the first
option poisition, so we press to paste "OneVar " onto the screen.
We complete the statement via the keys to generate the final
A.
|
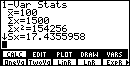
| Press the key to perform the command and the TI-86 responds with
Figure 4. In Figure 4 we note that the mean,
 key to move down to the additional items. key to move down to the additional items.
(The meaning of the |
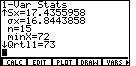
| In Figure 5 we have moved down the display three lines by pressing
the key 3 times. In addition, we have closed
the sub-menu by pressing the
 key. As a result, we can see more information about our
data set. Most important, we now see the line key. As a result, we can see more information about our
data set. Most important, we now see the line
|
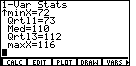
| We press the key 3 more times to arrive at Figure 6.
Here we find that the median is 110, the 3rd quartile point is 112, and the maximum is 116. |
We can look at the same data on a TI-83. The results will be the same but the steps are slightly different.
 |
Figure 1 shows the statement used to create a list, called L1,
which contains the
values in our data set. Note that the calculator started with a clear screen,
  keys to
generate the { and the keys to
generate the { and the
 keys to
generate the } symbols.
The comma was generated via the keys to
generate the } symbols.
The comma was generated via the  key.
The "store" symbol, key.
The "store" symbol,  key.
And we selected the standard list variable L1 via the key.
And we selected the standard list variable L1 via the
 key sequence. key sequence.
|
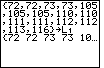 |
Figure 2 is a result of pressing the  key
to perform the command given in Figure 1. key
to perform the command given in Figure 1.
|
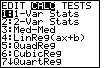 |
For Figure 3 we pressed the  key to open the
STATISTICS menu, and we have used the key. key to open the
STATISTICS menu, and we have used the key.
|
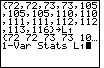 |
Figure 4 shows the 1-Var Stats command after we have pressed
to append the
L1 to it. This is the command that we will need to
run one-variable statistics on the data that is stored in the list
L1.
We press the key to perform that command.
|
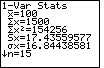 |
Figure 5 shows the first part of the output from the previous command. In
This case we see that the we note that the mean,
The final line of output on Figure 5,
(The meaning of the |
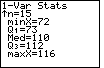 |
Figure 6 repeats the value for n, along with an "up-arrow" indicating that we could
move back to the Figure 5 output by using the
|
For your information, the web page bstat86.htm demonstrates the use of the TI-86 to find, among other things, the standard deviation (although not of the values in our example). The web page bstat85.htm demonstrates the use of the TI-85 to find, among other things, the standard deviation (although not of the values in our example). The web page begstat3.htm demonstrates the use of the TI-83 to find, among other things, the standard deviation (although not of the values in our example).
Let us return to the three data sets, C, F, and G, and look at the standard deviation of each set.
| Label | Standard Deviation |
| C | 521.114 |
| F | 243.903 |
| G | 251.530 |
The larger the standard deviation, the more disbursed the values. In our case, for three data sets all with the same mean, all with the same median, all with the same mode, and all with the same range, we can see that data set C has the largest standard deviation. Further, the standard deviations for data sets F and G are close, although the standard deviation of G is slightly larger than is the standard deviation of F. This corresponds to the "spread" of the values in these three data sets. Set C has many values that are far from the mean. Data sets F and G are different, but the differences are not as dramatic as are the differences between these and set C. If we look back at the second table on this page we can compare the standard deviation of each of the 7 data sets with the "spread" of values in those data sets. The standard deviation provides a single value that is representative of the "spread", the distribution, of the values in the data set. The smaller the standard deviaton, the closer the data values are to the mean.
Having looked at these measures of dispersion, we can not turn our attention to some basic methods for "Displaying Data".
©Roger M. Palay
Saline, MI 48176
September, 2013