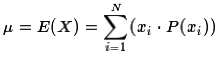
| Table 2 | ||||||||
| Values | 3 | 4 | 7 | 9 | 14 | 15 | 20 | 24 |
| Frequency | 2 | 2 | 2 | 4 | 3 | 2 | 1 | 1 |
| Probability | 2/17 | 2/17 | 2/17 | 4/17 | 3/17 | 2/17 | 1/17 | 1/17 |
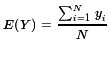 Then too, thinking about how we got the "sum of the yi's,
we could have found the same total by looking at the sum of the product of the values and their
respective frequencies,
Then too, thinking about how we got the "sum of the yi's,
we could have found the same total by looking at the sum of the product of the values and their
respective frequencies, 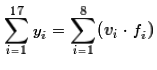 .
That means that we could rewrite the equation for expected value as
.
That means that we could rewrite the equation for expected value as
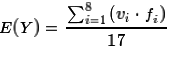 .
However, mathematically, because the denominator is a constant in the problem,
we can move the denominator into the summation to rewrite it as
.
However, mathematically, because the denominator is a constant in the problem,
we can move the denominator into the summation to rewrite it as
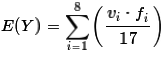 .
Then, rearranging the factors inside the summation we get
.
Then, rearranging the factors inside the summation we get
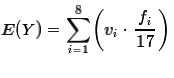 .
But the factor
.
But the factor
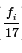 is just
the associated probability
is just
the associated probability
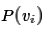 .
Making that change
and remembering that E(V)=E(Y) produces the form that we often see for the expected value,
namely,
.
Making that change
and remembering that E(V)=E(Y) produces the form that we often see for the expected value,
namely,
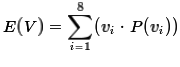 .
.

v<-c(3,4,7,9,14,15,20,24)
creates the data values in v.
The command f<-c(2,2,2,4,3,2,1,1)
creates the frequencies in f.
The next command, r<-rep(x,y),
uses the replicate function rep().
That function creates the long list of
the different values, each repeated the number of times
indicated by the corresponding frequency held in f.
The long list is stored in y.
We can see that long list
by just giving R the variable name y.
As we see, in Figure 1,
that list is exactly the list that we created by hand above.
Our goal was to find the mean of that expanded list of values.
We can do that in R by using the command mean(y).
The console image in Figure 1
shows that the mean, and thus
the expected value, is 10.58824.
.
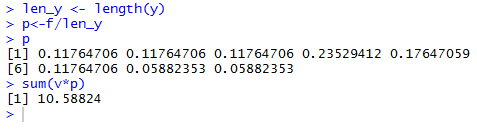
We need to create those probabilities. Each probability
is just the frequency divided by the number of items in the population.
There are many ways to get the number of items,
len_y<-length(y) being one of them.
Then the code p<-f/len_y
creates the probabilities and assigns them to p.
Therefore, we can have R perform this alternate computation of the
expected value by using the command sum(v*p). This is
shown in Figure 2.
| Version 1 | Version 2 |
| We have a game piece with 17 faces. The faces are marked with 3, 3, 4, 4, 7, 7, 9, 9, 9, 9, 14, 14, 14, 15, 15, 20, and 24, respectively. Each face is equally likely to "come up" when we roll the piece. | We have a game piece with 8 faces. The faces are marked 3, 4, 7, 9, 14, 15, 20, and 24, respectively. The game piece is "weighted" so that there is not an equal likelihood of "coming up" for each face. In fact, P(X=3)=2/17, P(X=4)=2/17, P(X=7)=2/17, P(X=9)=4/17, P(X=14)=3/17, P(X=15)=2/17, P(X=20)=1/17, and P(X=24)=1/17., |
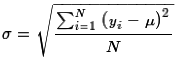 .
But, back in Figure 1, we actually created our yi's.
Therefore, we might assume that we can get the standard deviation
of our distribution by giving the command
.
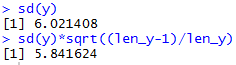
But, back in Figure 1, we actually created our yi's.
Therefore, we might assume that we can get the standard deviation
of our distribution by giving the command sd(y).
This does give us a value, as shown in Figure 3, but we have forgotten one thing.

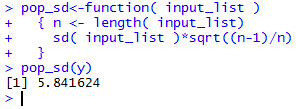
pop_sd<-function( input_list )
{ n <- length( input_list)
sd( input_list )*sqrt((n-1)/n)
}
If we have defined that function in our current session,
then we could get the result by using the command pop_sd(y).
All of this is shown in Figure 5.
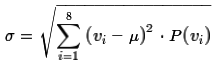 or the formula
or the formula
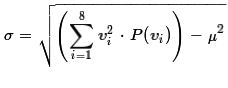 .
If we were doing the computation by hand the latter formula
is easier to use. As we see in Figure 6
we can easily use either formula in R.
.
If we were doing the computation by hand the latter formula
is easier to use. As we see in Figure 6
we can easily use either formula in R.

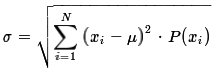
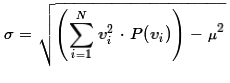
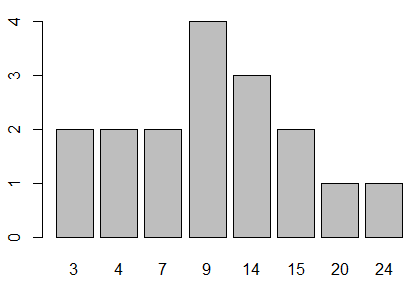
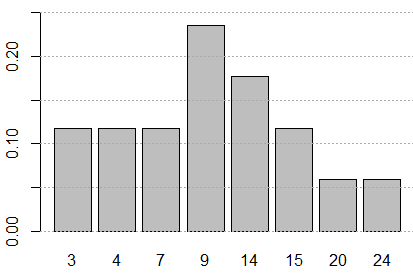
barplot(p,names.arg=v). The result is
shown in Figure 7.
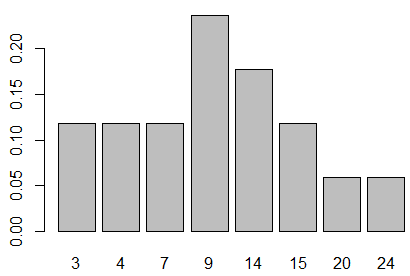
barplot(p,names.arg=v, ylim=c(0,.25)) abline(h=seq(0,.25,.05),col="darkgray", lty=3)produces Figure 8.
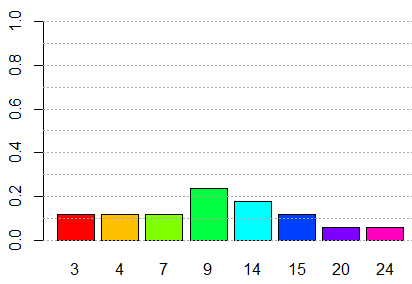
barplot(p,names.arg=v, ylim=c(0,1), col=rainbow(8)) abline(h=seq(0,1,.1),col="darkgray", lty=3)yields Figure 9. The vertical scale in Figure 9 was extended to run from 0 to 1, in part so that we can see that if we were to "stack up" all the bars, the total stack would be the full height of the plot. This should not be a shock since we know that the sum of all the probabilities must be 1.