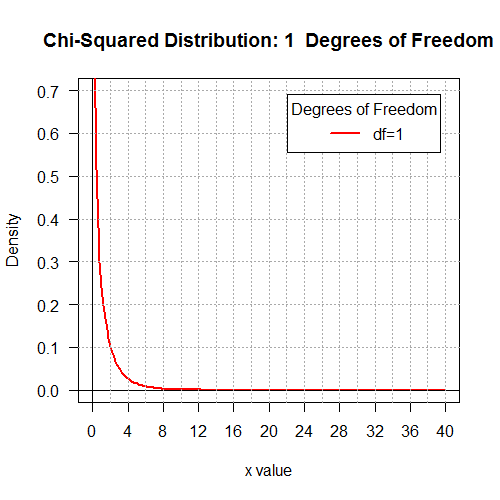
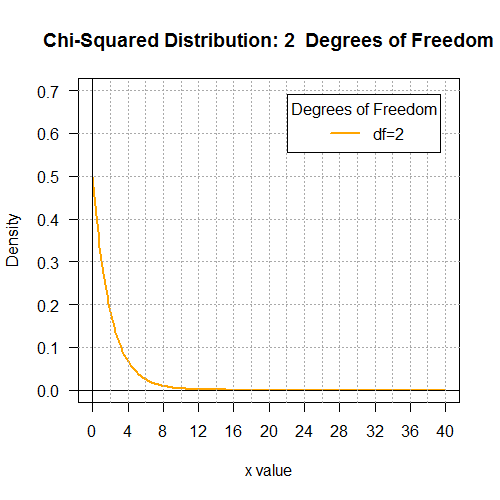
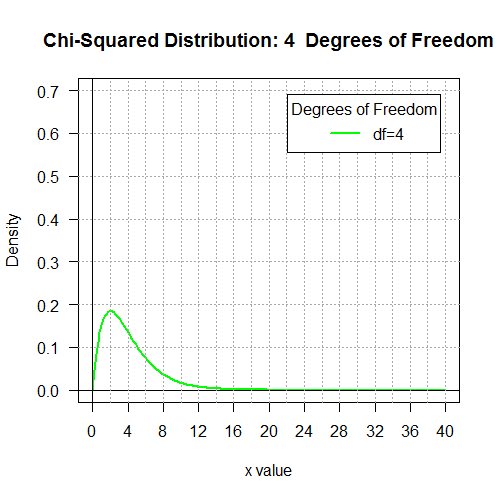
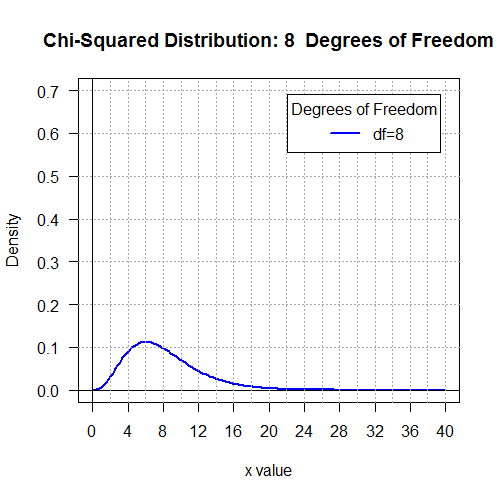
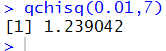
qchisq(0.01,7) asks R
to find the x-value that has 0.01 area to its left, with 7 degrees of freedom.
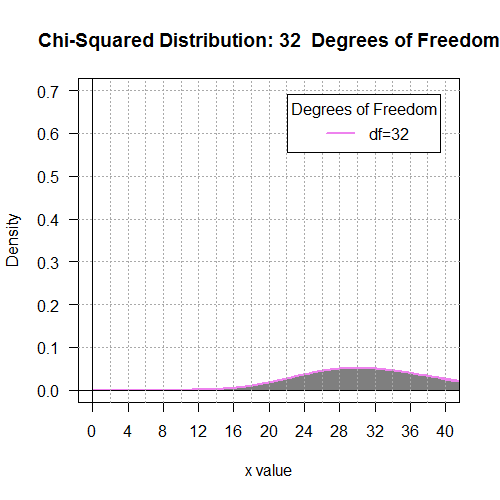
The result is shown in Figure 6.
Figure 6
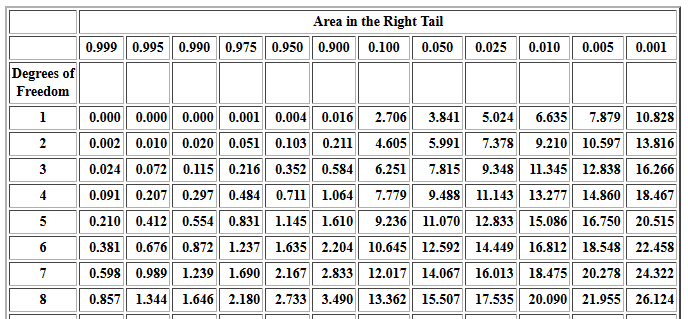
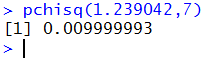
Recall that the table value had been 1.239 to produce
P(x < 1.239) = 0.01, but that our earlier use of
the command pchisq(1.239,7) had shown that this was not quite accurate.
Now we see that using the value 1.239042 should produce better results.
We can test that with the command
pchisq(1.239042,7)
to get the result shown in Figure 7.
Figure 7
We did not hit the target 0.01 but we are a lot closer than before.
All of this should remind us that we are always dealing in approximations for these values. Without infinite precision
we will never get infinitely accurate results.
However, the good news is that we rarely need anything like the extra
precision shown here. The table view kept us at 3 decimal places, and that is usually quite enough.
The default R view holds 7 significant digits and that will always be enough, though
we have seen that we can get even more digits displayed in R by changing the option
that controls the number of digits in the display.
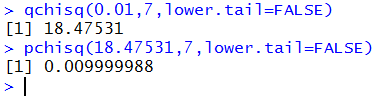
We should take note that by a simple change in the command to
qchisq(0.01,7,lower.tail=FALSE) we get the x-value
such that 1% of the area is to the right of that value, again for 7 degrees f freedom.
The console record of that command
and the confirming pchisq(18.47531,7,lower.tail=FALSE)
command is in Figure 8.
Figure 8
Sample Problems
We will solve the eight problems:
- For a χ² distribution with 6 degrees of freedom,
what is the probability of having a random event X be less than
2.34?
- For a χ² distribution with 9 degrees of freedom,
what is the probability of having a random event X be greater than
15.34?
- For a χ² distribution with 17 degrees of freedom,
what is the probability of having a random event X be less than
6.66 or greater than 27.34?
- For a χ² distribution with 14 degrees of freedom,
what is the probability of having a random event X be between
5.25 and 25.41?
- For a χ² distribution with 5 degrees of freedom,
what is the x-score that has 0.0333 square units under the curve and
to the left of that x-score?
- For a χ² distribution with 25 degrees of freedom,
what is the x-score that has 0.125 square units under the curve and
to the right of that x-score?
- For a χ² distribution with 11 degrees of freedom,
what are the x-scores that have 0.75 square units under the curve and
between those x-scores with the tails having equal areas?
- For a χ² distribution with 23 degrees of freedom,
what are the x-scores that have 0.0333 square units under the curve and
to the outside the interval between those
x-scores where the tails have equal areas?
1. The first problem becomes P(X < 2.34) for 6 degrees of freedom.
The R statement to get this value, pchisq(2.34,6),
and the answer are shown in Figure 9.
Figure 9

2. The second problem becomes P(X > 15.34)
for 9 degrees of freedom.
The R statement to get this value, pchisq(15.34, 9, lower.tail=FALSE),
and the answer are
shown in Figure 10.
Figure 10
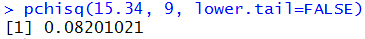
3. The third problem becomes
P(X < 6.66 or X > 27.34)
for 17 degrees of freedom.
The R statement to get this value,
pchisq(6.66, 17) + pchisq(27.34, 17, lower.tail=FALSE),
and the answer are
shown in Figure 11.
Figure 11
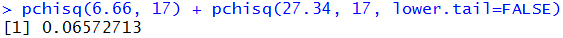
4. The fourth problem becomes
P( 5.25 < X < 25.41)
for 14 degrees of freedom.
The R statement to get this value,
pchisq(25.41, 14) - pchisq(5.25, 14),
and the answer are
shown in Figure 12.
Figure 12

5. The fifth problem becomes find a value for x such that
P(X < x) = 0.0333 for 5 degrees of freedom.
The R statement to get this value, qchisq(0.0333, 5),
and the answer are
shown in Figure 13.
Figure 13

6. The sixth problem becomes find a value for x such that
P(X > x) = 0.125 for 25 degrees of freedom.
The R statement to get this value,
qchisq(0.125, 25, lower.tail=FALSE),
and the answer are
shown in Figure 14.
Figure 14

7. The seventh problem becomes find a value for x1
and x2 such that
P(x1 < X < x2)= 0.75 for 11 degrees of freedom.
Stated that way there is no unique solution. However, the problem
statement included the stipulation that the area in the two tails needed to be equal.
But if the area between the two values is 0.75 then the
total tail area must be 0.25 square units.
Thus, the area to the left of x1 must be
0.125 square units and the area to the right of x2 must be
0.125 square units. This means that we have
P( X < x1 ) = 0.125 and
P( X > x2 ) = 0.125.
The R statements to get these values
are qchisq( 0.125, 11) and
qchisq( 0.125, 11, lower.tail=FALSE ).
Those statements and the answers are
shown in Figure 15.
Figure 15

8. The eighth problem becomes find values for x1
and x2 such that
P(X < x1) + P(X > x2)= 0.0333 for
23 degrees of freedom.
Stated that way there is no unique solution. However, the problem
statement included the stipulation that the area in the two tails needed to be equal.
Thus, the area to the left of x1 must be
0.01665 square units and the area to the right of x2 must be
0.01665 square units. This means that we have
P( X < x1 ) = 0.01665 and
P( X > x2 ) = 0.01665.
The R statements to get these values
are qchisq( 0.01665, 23) and
qchisq( 0.01665, 23, lower.tail=FALSE ).
Those statements and the answers are
shown in Figure 16.
Figure 16

Listing of all R commands used on this page
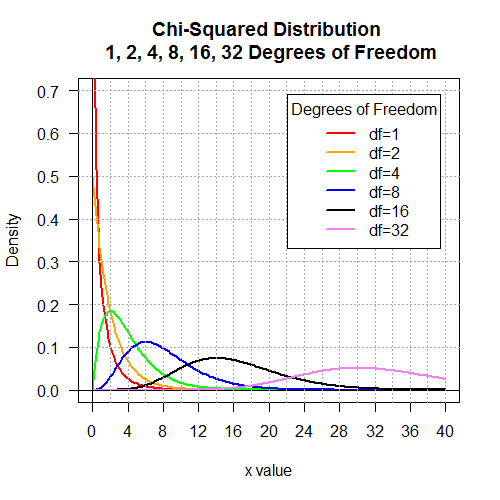
# Display the Chi-squared distributions with
# 1, 2, 4, 8, 16, and 32 degrees of freedom.
x <- seq(0, 40, length=200)
hx <- rep(0,200)
degf <- c(1,2,4,8,16,32)
colors <- c("red", "orange", "green", "blue", "black", "violet")
labels <- c("df=1", "df=2", "df=4", "df=8", "df=16", "df=32")
plot(x, hx, type="n", lty=2, lwd=2, xlab="x value",
ylab="Density", ylim=c(0,0.7), xlim=c(0,40), las=1,
xaxp=c(0,40,10),
main="Chi-Squared Distribution \n 1, 2, 4, 8, 16, 32 Degrees of Freedom"
)
for (i in 1:6){
lines(x, dchisq(x,degf[i]), lwd=2, col=colors[i], lty=1)
}
abline(h=0)
abline(h=seq(0.1,0.7,0.1), lty=3, col="darkgray")
abline(v=0)
abline(v=seq(2,40,2), lty=3, col="darkgray")
legend("topright", inset=.05, title="Degrees of Freedom",
labels, lwd=2, lty=1, col=colors)
for (j in 1:6 ){
plot(x, hx, type="n", lty=2, lwd=2, xlab="x value",
ylab="Density", ylim=c(0,0.7), xlim=c(0,40), las=1,
xaxp=c(0,40,10),
main=paste("Chi-Squared Distribution:",k[j]," Degrees of Freedom")
)
for (i in j:j){
lines(x, dchisq(x,degf[i]), lwd=2, col=colors[i], lty=1)
}
abline(h=0)
abline(h=seq(0.1,0.7,0.1), lty=3, col="darkgray")
abline(v=0)
abline(v=seq(2,40,2), lty=3, col="darkgray")
legend("topright", inset=.05, title="Degrees of Freedom",
labels[j], lwd=2, lty=1, col=colors[j])
}
# look at areas to the right of 4 for 6 different
# options on the degrees of freedom
pchisq(4,1, lower.tail=FALSE)
pchisq(4,2, lower.tail=FALSE)
pchisq(4,4, lower.tail=FALSE)
pchisq(4,8, lower.tail=FALSE)
pchisq(4,16, lower.tail=FALSE)
pchisq(4,32, lower.tail=FALSE)
# look at a left tail
pchisq(1.239,7)
qchisq(0.01,7)
pchisq(1.239042,7)
qchisq(0.01,7,lower.tail=FALSE)
pchisq(18.47531,7,lower.tail=FALSE)
pchisq(2.34,6)
pchisq(15.34, 9, lower.tail=FALSE)
pchisq(6.66, 17) + pchisq(27.34, 17, lower.tail=FALSE)
pchisq(25.41, 14) - pchisq(5.25, 14)
qchisq(0.0333, 5)
qchisq(0.125, 25, lower.tail=FALSE)
qchisq( 0.125, 11)
qchisq( 0.125, 11, lower.tail=FALSE )
qchisq( 0.01665, 23)
qchisq( 0.01665, 23, lower.tail=FALSE )
Return to Topics page
©Roger M. Palay
Saline, MI 48176 October, 2025