Why do we look at this as combinations? Really, we have five spots to fill,
one for each spin of the coin. If we call the spots a, b, c, d, and e,
then the question becomes which of the five slots get the 4 heads?
 |
|
Why do we look at this as combinations? Really, we have five spots to fill,
one for each spin of the coin. If we call the spots a, b, c, d, and e,
then the question becomes which of the five slots get the 4 heads?
|
|
Again, we have five spots to fill,
one for each spin of the coin. If we call the spots a, b, c, d, and e,
then the question becomes which of the five slots get the 3 heads?
|
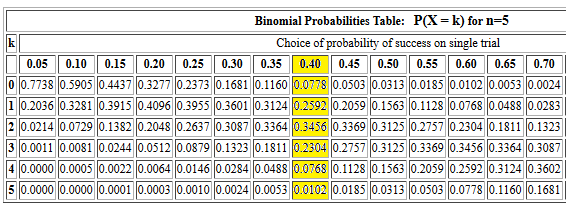
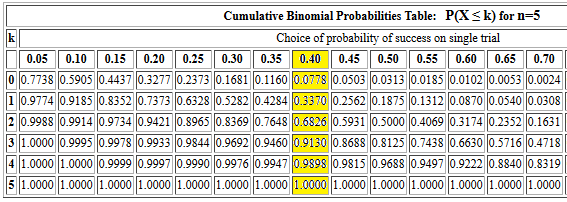
pbinom(3,5,0.40) should produce the same value that
we found in Figure 2 for the cumulative probability of getting 3 or fewer
successes out of 5 trials, each with a 0.40 probability of success.
The console record of that command is given in Figure 3.


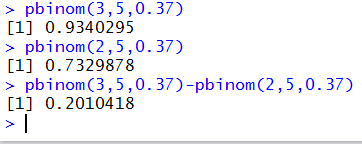
pbinom(3,5,0.37)-pbinom(2,5,0.37) as eventually shown in Figure 5.
pbinomeq <- function( k, n, p )
{
x<- pbinom(k,n,p)
if( k>0)
{ y <- pbinom(k-1, n, p)
x <- x - y
}
return( x )
}
The console image of defining the function is given in Figure 6.


pbinom(11,34,0.42)
will give us the answer 0.1672396.
pbinom(10,34,0.42).
The answer is 0.09292053.
pbinom(11,34,0.42)-pbinom(10,34,0.42) t get the answer
0.07431911. Alternatively, if we have loaded our function
pbinomeq() then we can use it as pbinomeq(11,34,0.42) to get
the same 0.07431911.
1-pbinom(11,34,0.42) which gives us
0.8327604. Alternatively, we could
look at this as the probability of
getting 12 or more successes. One might think that the
command pbinom(12,34,0.42,lower.tail=FALSE) would compute this.
However, the documentation for R states that
for the pbinom() function
lower.tail logical; if TRUE (default),
probabilities are P[X≤x], otherwise, P[X>x].
Therefore, if we specify lower.tail=FALSE we
will not be including
the first value since we are then looking at a "greater than" situation.
If we choose to use the lower.tail=FALSE option we need to
start at a value below 12. Therefore the command we want is
pbinom(11,34,0.42,lower.tail=FALSE)
which yields the same result, 0.8327604.
1-pbinom(10,34,0.42)
to get 0.9070795, or we could use the lower.tail=FALSE
approach , remembering to adjust the first argument to the function and use the
command pbinom(10,34,0.42,lower.tail=FALSE) to get 0.9070795.
1-pbinom(10,34,0.42) or pbinom(10,34,0.42,lower.tail=FALSE)
to get 0.9070795.
pbinom(11,34,0.42)
which gave us 0.1672396.
1-pbinomeq(11,34,0.42)
to get the answer 0.9256809.
pbinom(18,34,0.42)-pbinom(10,34,0.42) to get the result
0.8349292.
pbinom(17,34,0.42)-pbinom(11,34,0.42) to get the result
0.7008324.
1-(pbinom(18,34,0.42)-pbinom(10,34,0.42)) which gives
the answer 0.1650708.
1-(pbinom(17,34,0.42)-pbinom(11,34,0.42)) which gives
the answer 0.2991676.