Percentiles -- Quantiles
Return to Topics page
Earlier we looked at the median of a collection
of data values.
Conceptually, the median has half the data with a value smaller than
the median
and half the data with a value larger than the median.
Later we looked at the quartile values where the
first quartile, denoted as Q1, has a
quarter of the data values less than Q1 and three-quarters
of the data values larger than Q1, and the
third quartile, denoted as Q3 has three
quarters of the data values smaller than Q3 and one quarter
of the values larger than Q3.
Q2 is just the median so, again, it has half the values
being smaller and half the values being larger. We can
capture this in a table.
| Table 1 |
Quartile
Name | Percent of Values
Less Than the
Quartile Value
|
| Q1 | 25% |
| Q2 | 50% |
| Q3 | 75% |
As we review the median and quartiles we recall that they
require us to sort the values before we can determine values for the
median and quartiles.
For example, consider the values in Table 2.
In order for us to find the median and quartiles we sort the values
to get
Finding the first and third quartile values is not so easy.
In fact, as was discussed in an earlier page, there is not even a single
generally agreed upon rule for finding those values. One method, not the one
used by R, is to find the middle value of the values below the median
and call that the first quartile. Similarly, that method looks at the middle
of the values above the median
and calls that the third quartile. In our case that puts
the first quartile as the value in position
All of the review of the median and quartile
values sets the stage for discussing percentiles.
In the sorted list, just as Q3 has 75% of the items below it,
Q2, the median, has 50% of the items below it, and
Q1 has 25% of the items below it,
the 95th percentile is the value that has 95% of the items below it,
the 40th percentile is the value that has 40% of the items below it, and
the 27th percentile is the value that has 27% of the items below it.
Upon reflection, the 40th percentile has `2/5` of the values
below it. Therefore, we know that the computed value
has to be strange if we have fewer than `5` values in the table.
Similarly, the 95th percentile has `19/20` of the values
below it. Therefore, we know that the computed value
has to be strange if we have fewer than `20` values in the table.
And, of course, the 27th percentile has `27/100` of the values
below it. Therefore, we know that the computed value
has to be strange if we have fewer than `100` values in the table.
The strangeness of such computations extends to
any size collection, and it does so to the extent that there are
at least 9 different methods for calculating percentiles.
However, for large collections of values all of the different methods
yield at least similar results.
Percentiles make the most sense if we have a really large collection
of values.
The values in Table 4 represent a large, but by no means huge,
collection. (You will, of course, need to scroll through the text area to
see all of the values in the table.)
| Table 4: R style listing of the original 348 values
|
|
|
Although it is good to see the original data, as in Table 4,
in order or us to find the percentiles
of these values we will need a sorted listing of them.
We have such a listing, of the same values,
in Table 5.
| Table 5: R style listing of the sorted 348 values
|
|
|
Table 5 presents, in the R style of presenting
values, an ordered list of all 348 values. The
95th percentile of these
must be a value that has 95% of the values as
less than this 95th percentile value.
But that means that we just have to find the
value in the 95% of 348 position in the listing.
95% of 348 = 0.95*348 =330.6.
Clearly, there is no item in position 330.6, but there is
an item in position 330, namely 667, and there is an
item in position 331, namely 669.
Which value we choose, or what value around 668 we choose
depends on which of those 9 different rules that we want to use.
However, it is safe to say that nobody is really going to care
all that much if we just choose 669 as being the
95th percentile. As we will see later,
if we were to ask R to compute the
95th percentile it would give us the value
668.3.
How about finding the 40th percentile?
We just compute
40% of 348 = 0.4*348 =139.2.
Again, there is no item in position 139.2, but there is
an item in position 139, namely 476, and there is an
item in position 140, namely 476.
We could justifiably choose 476 as the answer,
and R will also choose 476.
To find the 27th percentile
we compute
27% of 348 = 0.27*348 =93.96.
There is no item in position 93.96, but there is
an item in position 93, namely 444, and there is an
item in position 94, namely 445.
It would be reasonable to choose 445 as the answer.
However, R will choose 445.69.
Quantiles vs. Percentiles
So far we have just talked about percentiles.
The title of this page includes quantiles. What is the difference?
Not much. Percentiles are given as percent values, values such as 95%,
40%, or 27%. Quantiles are given as decimal values, values such as 0.95,
0.4, and 0.27. The 0.95 quantile point is exactly the same as the
95th percentile point.
R does not work with percentiles, rather R works with
quantiles. The R command for this is
quantile() where we need to give that function the
variable holding the data we are using and we need to give
the function one or more decimal values.
Interestingly, the quantile() function returns the
desired value but it does so with a name in the form of a percentage.
We will look at an example.
First, we need to get the values in our table.
The R command set.seed(34211)
is used to set a starting point for the pseudo-random number
generator that R uses. By setting the seed
value we create an environment where the subsequent generation of
seemingly random values is completely determined. That way,
should we or someone else, want to replicate our steps, the
random numbers we or they get will be exactly the same as
the values we will see here.
Figure 1 starts with that statement.
Figure 1

Figure 1 ends with a statement,
mylist <- round( rnorm(348, mean=500, sd=100 ) )
that generates 348 random values such that those values will
have a mean of approximately 500 and a standard deviation of approximately 100.
Those 348 random values are then rounded to be 348 random integers.
Finally, those values are assigned to the variable mylist.
Once defined, we can ask to see the values by using the mylist
command. The result is shown in Figure 2.
Figure 2

You will notice that he values in Figure 2 are identical to
those in Table 2. In fact they are identical because the text
in Figure 2 was copied and placed in this
web page as the data behind Table 2.
There is no need to do the actions shown in Figures 3 and 4,
but doing them allows us to verify the contents of Table 3.
In Figure 3 we use the sort() function to sort the values
stored in mylist. We assign those sorted values to the
variable mylist_sorted.
Figure 3
Then, in Figure 4, we use the command mylist_sorted
to display the entire sorted collection of values.
Figure 4
To actually find a percentile value for mylist
we ask for the corresponding quantile by using the quantile()
function. Figure 5 shows the command to get the
95th percentile of mylist,
along with the resulting value.
Figure 5
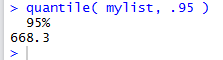
Note how the quantile(mylist,.95) command
produces output that is actually labeled as
95%. The value is the same 668.3 that was noted above.
We could give quantile() more than one value by
using the c() function to combine
those values into one argument as in
quantile(mylist,c(.95,.40,.27)),
the statement shown in Figure 6.
Figure 6

As you can see, the statement produces the percentile
values that we expect.
We could take the idea of giving quantile() many
values to a higher level.
The statement quantile(mylist,seq(0.05,0.95,0.05))
asks R to compute percentile values
for 5%, 10%, 15%, and so on up to 95%.
The command and its related output are shown in Figure 7.
Figure 7
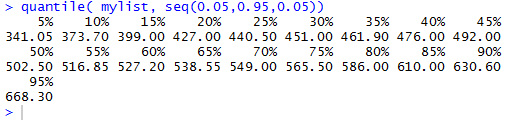
The output in Figure 7 gives us all of the values that we requested.
However, it might be nice if we could convert this to a vertical format.
The statements shown in Figure 8 recompute the percentiles
that we just found, but store the results in the variable qtile.
Then, the statements pull out the names and the values in qtile,
concluding with the creation of a data frame,
that is then stored in the variable qdf.
Figure 8

Then, the statement qdf produces the vertical listing we desired.
Figure 9
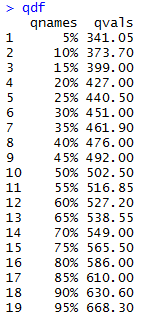
Of course, the labels on the top of the values come from the
names of the variables we used to create the data frame.
We can use the names() function to change those titles to
something more appropriate.
This is done in Figure 10.
Figure 10
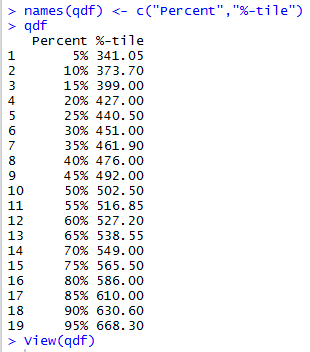
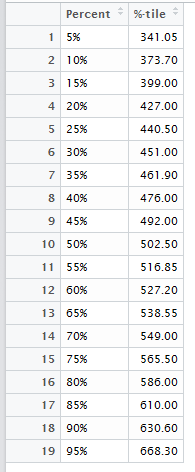
Now that the data frame is defined
we can use the View(qdf) to produce the
"pretty" output shown in Figure 11.
Figure 11
The work that we have seen so far has fallen into the form: Here is a list of
data values, now find the nth percentile of that data
(using the quantile() function). We can, and often do, turn that question around.
For example, with the data given in Figure 4, we might ask
"What percentile is the value 432?"
That is an especially nice value because 432 is
not a value in Figure 4. Remembering that the values in Figure 4 are already
sorted, we can see that there are 75 values that are less than 432. Therefore,
since there are 348 values in the table, it makes sense to say that 75/348 ≈ 0.2155 or
21.55% of the values are less than 432, or that 432 is the 21.55 percentile.
This gets more complicated if the value we are using is in the table,
and especiallycomplicated if the value is repeated in the table.
For example, what percentile should we assign to 528? There are 209
values less than 528
but 528 occupies positions 210, 211, 212, and 213 of the sorted list.
As we might expect, there are any number of "rules" that might guide us to
an answer for this kind of situation. Because there is no definitive universally
accepted rule, we can come up with
one that serves our purpose. Our rule will give an answer that, in all but the most
contrived situations, will be close to the answer that any of the other generally
accepted rules produce. Our rule is captured in the function
find_percentile().
We need to give that function the list of values
(it does not even have to be a sorted list) and the value
for which we want to determine a pecentile.
Thus the statements
source( "../find_percentile.R")
find_percentile( mylist, 432)
find_percentile( mylist, 528)
find_percentile( mylist, 562)
will return the percentile to be assigned to the values 432, 528, and 562.
This is shown in Figure 12.
Figure 12
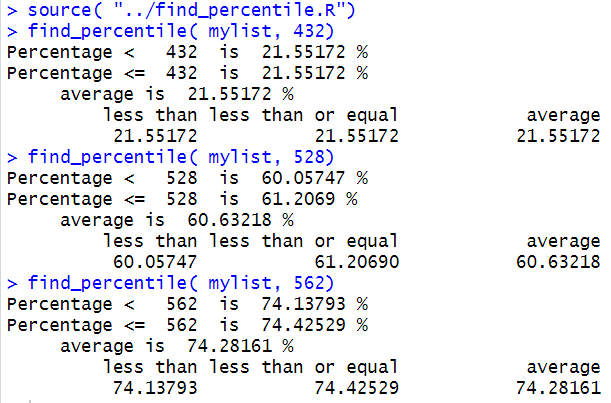
Here is a listing of the R statements used on this percentage
# for the percentile web page
set.seed(34211)
mylist <- round( rnorm(348, mean=500, sd=100 ) )
mylist
mylist_sorted <- sort( mylist )
mylist_sorted
quantile( mylist, .95 )
quantile(mylist,c(.95,.40,.27))
quantile(mylist,seq(0.05,0.95,0.05))
qtile <- quantile(mylist,seq(0.05,0.95,0.05))
qnames <- names(qtile)
qvals <- as.numeric(qtile)
qdf <- data.frame(qnames,qvals)
qdf
names(qdf) <- c("Percent","%-tile")
qdf
View(qdf)
source( "../find_percentile.R")
find_percentile( mylist, 432)
find_percentile( mylist, 528)
find_percentile( mylist, 562)
Return to Topics page
©Roger M. Palay
Saline, MI 48176 June, 2021