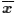 , we either reject H0 in favor of
H1, or we
do not reject H0 in favor of
H1.
Certainly, if our sample had an average year of 1975 we might think that
H0 is wrong, but we would
not reject H0 in favor of
H1, an alternative that suggests
that the mean is less than 1968. Because we only have two alternatives,
H0 and H1,
the fact that H0 is expressed using equality,
H0: μ=1968,
does not mean that we have to hit 1968 exactly to favor
H0 over H1.
Were we to get a sample mean year of 1967.78 then intuitively,we would not want
to suggest that the null hypothesis is wrong.
On the other hand,
were we to get a sample mean year of 1923 then we would certainly
reject H0 in favor of H1
because 1923, as an average of 32 coin years, is so extremely far from 1968.
But what do we do with an average of 1961.908?
We can sum up the situation by looking at Table 2.
, we either reject H0 in favor of
H1, or we
do not reject H0 in favor of
H1.
Certainly, if our sample had an average year of 1975 we might think that
H0 is wrong, but we would
not reject H0 in favor of
H1, an alternative that suggests
that the mean is less than 1968. Because we only have two alternatives,
H0 and H1,
the fact that H0 is expressed using equality,
H0: μ=1968,
does not mean that we have to hit 1968 exactly to favor
H0 over H1.
Were we to get a sample mean year of 1967.78 then intuitively,we would not want
to suggest that the null hypothesis is wrong.
On the other hand,
were we to get a sample mean year of 1923 then we would certainly
reject H0 in favor of H1
because 1923, as an average of 32 coin years, is so extremely far from 1968.
But what do we do with an average of 1961.908?
We can sum up the situation by looking at Table 2.| Table 2 | ||
| The Truth (reality) | ||
| Our Action | H0 is TRUE | H0 is FALSE |
| Reject H0 | This is a Type I error |
made the correct decision |
| Do not Reject H0 |
made the correct decision |
This is a Type II error |