| Figure 1 |
|
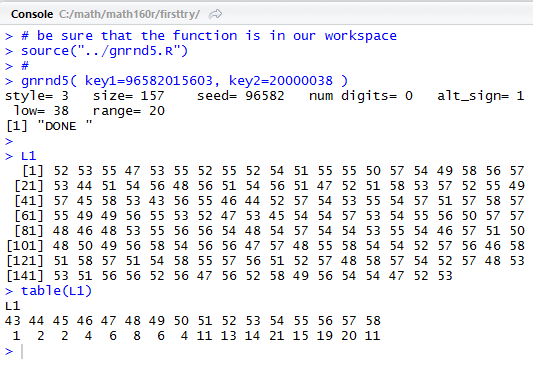
L1 (this
is the standard place that gnrnd5 creates the values)
and and then display
those values as shown in Figure 1.
| Figure 1 |
|
|
table(L1) command showing the frequency of each value
in the vector.
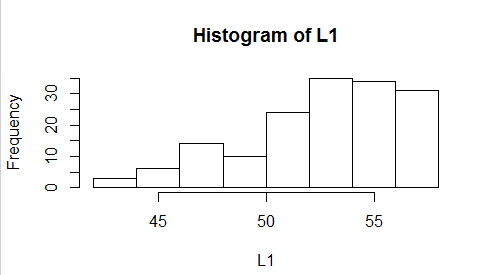
This confirms the "left-skewed" distribution.
To see more evidence of this distribution we could
use the simple hist(L1) command to produce
Figure 2.
| Figure 2 |
|
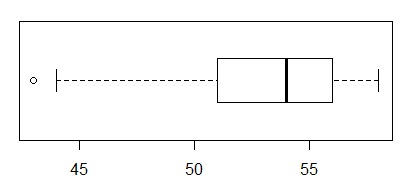
boxplot(L1,horizontal=TRUE) command to produce
Figure 3.
| Figure 3 |
|
source("../gnrnd5.R")
gnrnd5( key1=260561003006, key2=3120027016012, key3=1290000570 )
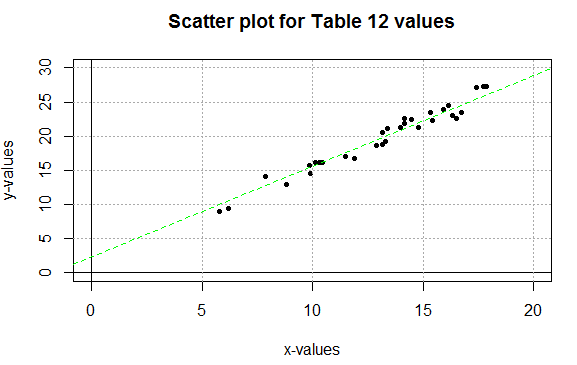
plot(L1,L2, xlab="x-values", ylab="y-values",
main="Scatter plot for Table 12 values",
xlim=c(0,20), ylim=c(0,30), pch=20
)
abline(h=0,v=0)
abline(h=seq(5,30,5),lty="dotted", col="darkgray")
abline(v=seq(5,20,5),lty="dotted", col="darkgray")
abline(9/4, 4/3, col="green", lty="dashed")
produced the following plot in Figure 4. Note that the goal relationship
is shown as a dashed green line in the plot. That is the goal relationship
not the linear regression line.
| Figure 4 |
|
| Key 1 |
d | d d d d d | d d d d | d d |
| num digits | initial seed value | (generated sample size)-1 | style | |
| Number of decimal digits implied in some second key values and used in generating the actual values in some cases. Also used to determine if certain second key values are negative. Values 0, 1, 2, 3, and 4 represent, respectively 0, 1, 2, 3, or 4 decimal digits. Values 5, 6, 7, 8, 9 represent, respectively, 0, 1, 2, 3, or 4 decimal digits, but with the understanding that some second key values may be negative. | The initial seed value. Generally this is determined by some other random number generator. The value used here then determines the sequence of random values generated by the appropriate functions both in the TI-83/84 program and in the web page. | One less than the desired sample size. Thus a 4-tuple of digits such as 0311 will generate a 312 item sample, a 4-tuple of digits such as 9932 will generate a 9933 item sample, and a 4-tuple of digits such as 0003 will generate a 4 item sample. | The style selector. This gives us room for up to 99 different
styles of samples. Initially there are 10 defined styles,
As more styles are specified this list will expand,
Current styles are
|
| Style | Name | Text | |
| 01: | Uniform | A uniform distribution gives an equally likely probability of having each permissible greater than or equal to some specified Low value and a High value determined to be the Low+Range for some specified Range, This is accomplished by taking a uniformly distributed random value between 0 and 1 and applying it to the Range, adding the result to the Low value, and then rounding the result to the specified number of digits. | |
| 02: | Power | This power distribution is identical to the uniform distribution except that the random value that is generated is squared before it is used to scale the Range. The result, since the random values generated initially are between 0 and 1, is to have a distribution that favors low values. | |
| 03: | Root | This power distribution is identical to the uniform distribution except that we take the quare root of the random value that is initially generated before it is used to scale the Range. The result, since the random values generated initially are between 0 and 1, is to have a distribution that favors high values. | |
| Key 2 | d d d d d d | d d d d d d | |
| These six digits specify the Range of values that may be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 (which could be specified simply as 100) would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 7. | These six digits represent the Low end of the permisible values to be generated. Note that if the number of digits specied in Key 1 came from a value greater than 4 then this Low values is set to be a negative, Thus, 120000 with the number of decimal digits given as a 6, has an implied decimal value of 1200.00, but it is a negative value, that is, -1200.00. | ||
| Style | Name | Text | |||||||||
| 04: | Normal | The program generates values that are approximately normally distributed with a specified mean and a specified standard deviation. | |||||||||
| Key 2 | d d d d d d | d d d d d d | |||||||||
| These six digits specify the goal Standard Deviation of values to be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 (which could be specified simply as 100) would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 7. | These six digits specify the goal Mean of values to be generated. Note that if the number of digits specied in Key 1 came from a value greater than 4 then this Mean values is set to be a negative, Thus, 020000 with the number of decimal digits given as a 6, has an implied decimal value of 200.00, but it is a negative value, that is, -200.00. | ||||||||||
| Style | Name | Text | |||||||||
| 05: | Bi-Modal | The program generates values that are randomly selected from two approximately normal distributions, each with its own specified mean and standard deviation. Key 2 will give the mean and standard deviation for one distribution, while Key 3 will give the mean and standard deviation for the other distribution. As it generated each value, the process randomly selects which distribution to use. As such, the number of values from each distribution is a random choice and there is no attempt to have an approximately equal number of values from each distribution. | |||||||||
| Key 2 | d d d d d d | d d d d d d | |||||||||
| These six digits specify the first goal Standard Deviation of values to be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 (which could be specified simply as 100) would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 7. | These six digits specify the first goal Mean of values to be generated. Note that if the number of digits specied in Key 1 came from a value greater than 4 then this Mean values is set to be a negative, Thus, 320000 with the number of decimal digits given as a 6, has an implied decimal value of 3200.00, but it is a negative value, that is, -3200.00. | ||||||||||
| Key 3 | (-) d d d d d d | d d d d d d | |||||||||
| These six digits specify the goal Standard Deviation of values to be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 (which could be specified simply as 100) would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 7. The negative sign, if present has no effect on the standard deviation, rather, if there is a leading negative sign then the value of the mean, the last six digits, is made negative. | These six digits specify the second goal Mean of values to be generated. Note that, unlike the first goal mean, this one is turned negative by preceding the entired specified key value with a negative sign. | ||||||||||
| Style | Name | Text | |||||
| 06: | Linear | The linear distribution generates pairs of values, (x,y), such that there is a y=mx+b underlying relationship between the values. To generate our distribution we need to have a Low value for the x-values, a Range for the x-values, a specification for the linear relationship, given as Dy =Mx+B, and an indicator for the maximum amount of error to introduce. The Low and Range values are given in Key 3 while the other valeus are specified in Key 2. | |||||
| Key 2 | d | d | d | d d d d | d d d | d d d | |
| This is a single digit error factor. To calculate the maximum allowed error on any one observation, if E is this digit, find (E+1)(E+2)/200 and apply that to the max change in the model from the Left x value to the Right x value. | This digit indicates the sign of the B value: 0-5=positive; 6-9=negative. | This digit indicates the sign of the M value: 0-5=positive; 6-9=negative. | These four digits give the value of B in Dy=Mx+B, possibly negated from earlier indicator. | These three digits give the value of M in Dy=Mx+B, possibly negated from earlier indicator. | These three digits give the value of D in Dy=Mx+B. | ||
| Key 3 | d d d d d d | d d d d d d | |||||
| These 6 digits give the Range of the x-values. Note that this value is scaled by the number of decimal digits specified in Key 1. | These 6 digits give the Low value of the x-values. Note that this value is scaled by the number of decimal digits specified in Key 1. In addition, this value may be changed to a negative value based on that same Key 1 value. | ||||||
| Style | Name | Text | |||||||||
| 07: | Discrete | The discrete distribution generates values from 1 to the number of categories in an approximation to the relative frequency given for each of the categories. There should be at least two categories and there can be as many as nine categories. The number of categories and the relative frequencies, as single digits, for each category are given in Key 2. | |||||||||
| Key 2 | d | d | d | d | d | d | d | d | d | d | |
| Relative Freq cat 9 | Relative Freq cat 8 | Relative Freq cat 7 | Relative Freq cat 6 | Relative Freq cat 5 | Relative Freq cat 4 | Relative Freq cat 3 | Relative Freq cat 2 | Relative Freq cat 1 | # of cat | ||
| Style | Name | Text | |||||||||
| 08: | Table |
The Table distribution fills a table with the number of
times a value has been observed in each cell of the table.
This is done with a goal of having a certain relative
frequency in each row and certain relative
frequency in each column of the table.
The second Key gives the number of rows and the number of
columns, along with a relative frequency of each. The specification
below for that second key implies that the sum of the number of rows and number
of columns should not excede eight (8). In fact, it can be 14.
A further note is that the actual number of "observations" is equal to the "size" as given in Key 1 times the number of rows times the number of columns. This is done because having so many cells in a table means that the "observations" are spread out over many cells. Using this factor approach allows us to get much larger values. | |||||||||
| Key 2 | d | d | d | d | d | d | d | d | d | d | |
| Relative Freq col n | Relative Freq col n-1 | Relative Freq col n-2 | Relative Freq | Relative Freq | Relative Freq | Relative Freq row 2 | Relative Freq row 1 | # of cols | # of rows | ||
| As implied above, these 8 digits hold the relative frequencies of the rows and columns. Reading right to left we find the relative frequency of row 1, row 2, and so on until we are done with the row values. Then we start with the column relative frequencies. Since there are but 8 digits in this group, we want the number of rows plus the number of columns to be no more than 8. The actual limit is 14, but the documentation here is a bit easier if we show only 8. | |||||||||||
| Style | Name | Text | |||||
| 09: | Quartile | The Quartile Points distribution chooses random values from the Low value to the Low+Range value such that we have Quartile points set at a specified percent across the range of values. Thus, we could have a range of 300 and specify quartile widths (i.e., the span) at 50%, 15%, 25%, and 10%. These correspond to a span of 150, 45, 75, and 30. The range of values is divided accordingly. Quartile points are set, remaining values are allocated. The values are placed in the list in random order. Also, If the IQR is such that 1.5*IQR does not cover the first or fourth quartile, then the program ensures that there is one point in the outlier region. Finally, the specified size for the sample is always rounded up to one less than the next multiple of 4. | |||||
| Key 2 | pp | pp | pp | d d d d | d d d d | ||
| This is the percent of the range given to the first quartile. | This is the percent of the range given to the second quartile. | This is the percent of the range given to the third quartile. Note that the fourth quartile gets the remaining part of the range. | These four digits give the range, possibly altered by the number of decimal digits. | These four digits give the low value, possibly altered by the number of decimal digits. | |||
| Style | Name | Text | |||
| 10: | Paired Normal | The program generates values that are approximately normally distributed with a specified mean and a specified standard deviation. In addition, the program generates a second list with values paired to the first list. | |||
| Key 2 | d d | d d d d d d | d d d d d d | ||
| These two digits specify the spread of the paired values. In particular, values near 00 produce almost no spread while values near 99 produce a great spread and one that is shifted to have the second value tending to be greater than the first. | These six digits specify the goal Standard Deviation of values to be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 000100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 8. | These six digits specify the goal Mean of values to be generated. Note that if the number of digits specied in Key 1 came from a value greater than 4 then this Mean values is set to be a negative, Thus, 020000 with the number of decimal digits given as a 7, has an implied decimal value of 200.00, but it is a negative value, that is, -200.00. | |||