GNRND4 on the TI-83/84 calculator, or using gnrnd4()
in an R script.
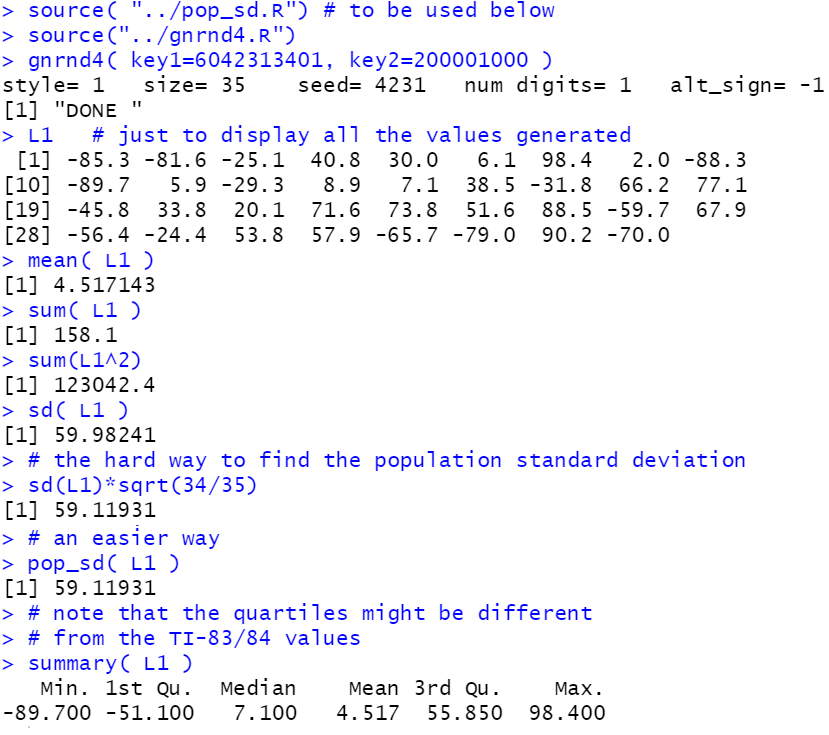
source( "../pop_sd.R") # to be used below
source("../gnrnd4.R")
gnrnd4( key1=6042313401, key2=200001000 )
L1 # just to display all the values generated
mean( L1 )
sum( L1 )
sum(L1^2)
sd( L1 )
# the hard way to find the population standard deviation
sd(L1)*sqrt(34/35)
# an easier way
pop_sd( L1 )
# note that the quartiles might be different
# from the TI-83/84 values
summary( L1 )
Figure 1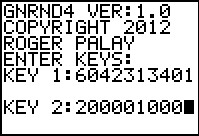 |
Figure 2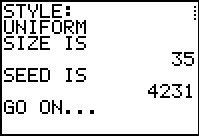 |
Figure 3 |
Figure 4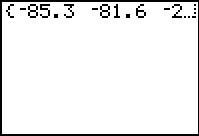 |
Figure 5 |
Figure 6 From STAT EDIT 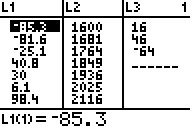 |
| Figure 7 From 1-Var Stats 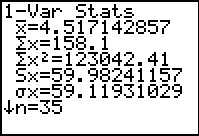 |
Figure 8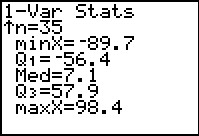 |
# Generate a skewed left set of values
# this assumes we have loaded gnrnd4() into our environment
gnrnd4( key1=7042313702, key2=200001000 )
L1 # just to display all the values generated
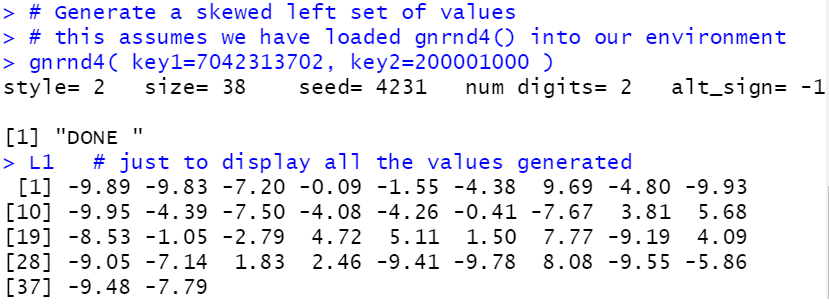
Figure 9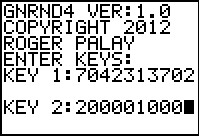 |
Figure 10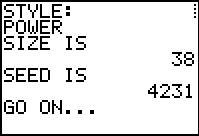 |
Figure 11 |
Figure 12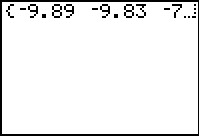 |
Figure 13 From STAT EDIT 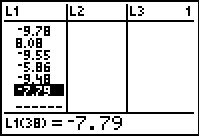 |
# Generate a skewed right set of values
# this assumes we have loaded pop_sd() into our environment
# this assumes we have loaded gnrnd4() into our environment
gnrnd4( key1=042312603, key2=20000100 )
L1 # just to display all the values generated
mean( L1 ) # to find the mean
sum( L1 ) # to find the sum of the values in L1
# to find the sum of the squares
sum( L1^2 ) # of the values in L1
# to find the standard deviation
sd( L1 ) # if this is a sample
# to find the standard deviation
pop_sd(L1) # if this is a population
summary(L1)# finds lots of values
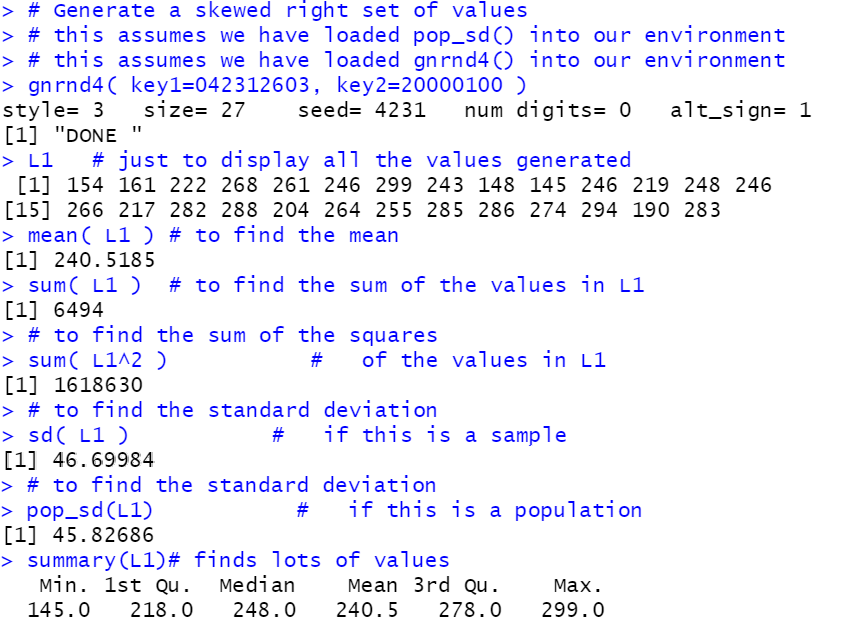
Figure 14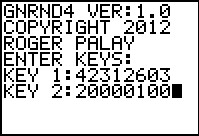 |
Figure 15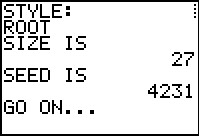 |
Figure 16 |
Figure 17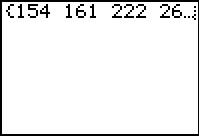 |
Figure 18 From STAT EDIT 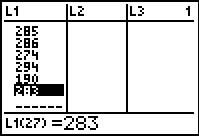 |
Figure 19 From 1-Var Stats 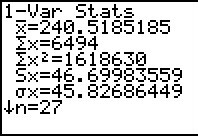 |
Figure 20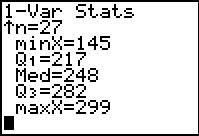 |
# Generate an approximately normal set of values
# this assumes we have loaded pop_sd() into our environment
# this assumes we have loaded gnrnd4() into our environment
gnrnd4( key1=3042314404, key2=0320010000 )
L1 # just to display all the values generated
mean( L1 ) # to find the mean
sum( L1 ) # to find the sum of the values in L1
# to find the sum of the squares
sum( L1^2 ) # of the values in L1
# to find the standard deviation
sd( L1 ) # if this is a sample
# to find the standard deviation
pop_sd(L1) # if this is a population
summary(L1)# finds lots of values

Figure 21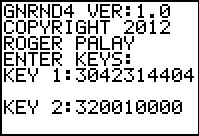 |
Figure 22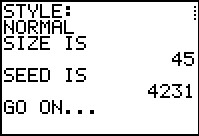 |
Figure 23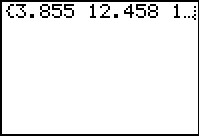 |
Figure 24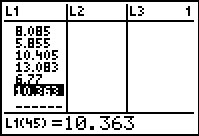 |
Figure 25 From 1-Var Stats 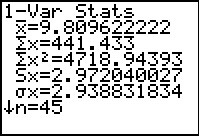 |
Figure 26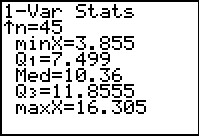 |
# Generate an approximately bimodal set of values
# this assumes we have loaded pop_sd() into our environment
# this assumes we have loaded gnrnd4() into our environment
gnrnd4( key1=1042315305, key2=10000300, key3=5000400 )
L1 # just to display all the values generated
mean( L1 ) # to find the mean
sum( L1 ) # to find the sum of the values in L1
# to find the sum of the squares
sum( L1^2 ) # of the values in L1
# to find the standard deviation
sd( L1 ) # if this is a sample
# to find the standard deviation
pop_sd(L1) # if this is a population
summary(L1)# finds lots of values
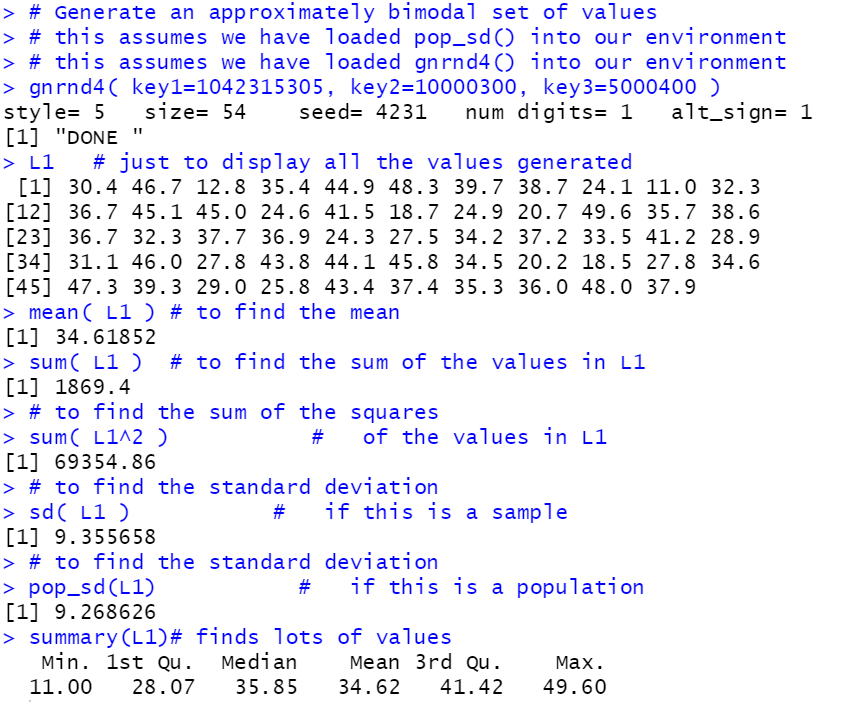
Figure 27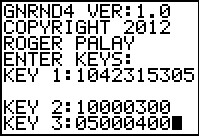 |
Figure 28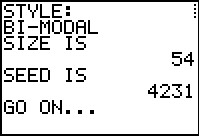 |
Figure 29 |
Figure 30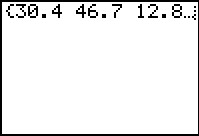 |
Figure 31 From STAT EDIT 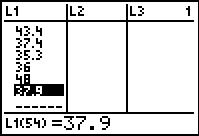 |
Figure 32 From 1-Var Stats 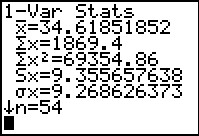 |
# Generate a set of pairs of values that have
# an approximately linear relation.
# this assumes we have loaded pop_sd() into our environment
# this assumes we have loaded gnrnd4() into our environment
gnrnd4( key1=1042311806, key2=3120040503, key3=20000100 )
L1 # just to display all the x values generated
L2 # just to display all the y values generated
lm(L2~L1) # to show the coefficients in y=a + b*x
cor( L1,L2) # the correlation coefficient, r
cor(L1,L2)^2 # the value of r^2
plot(L1,L2) # a scatter plot
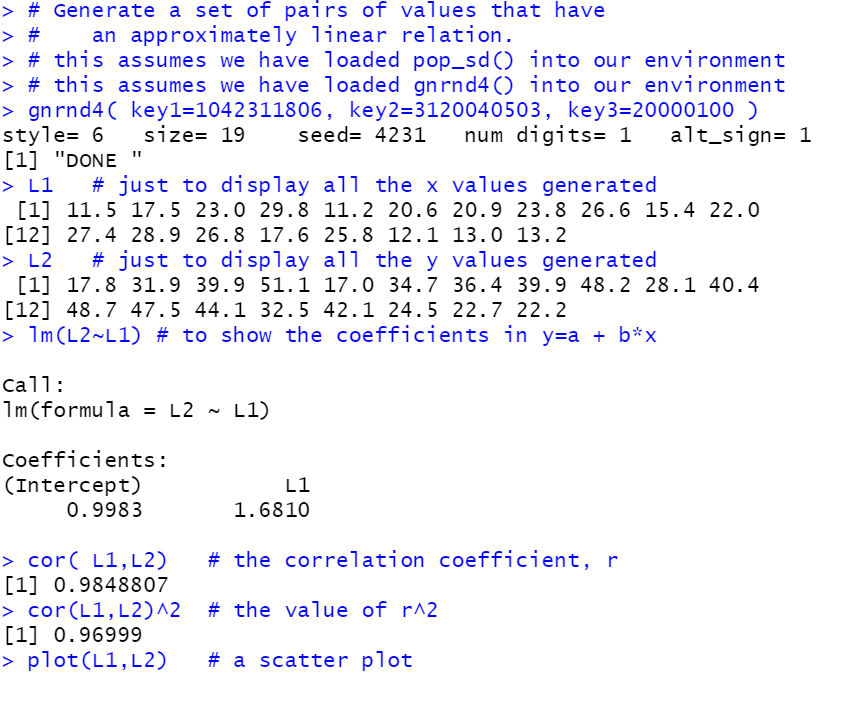
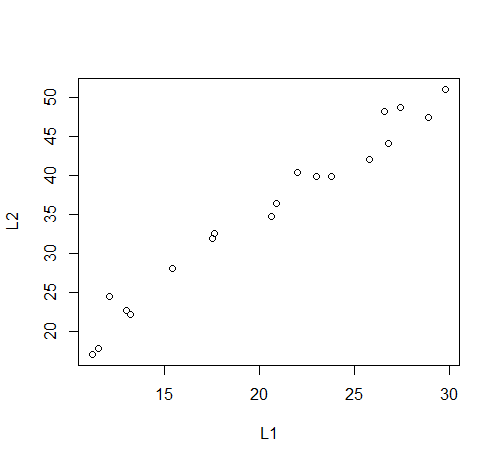
Figure 33 |
Figure 34 |
Figure 35 |
Figure 36 |
Figure 37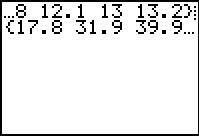 |
Figure 38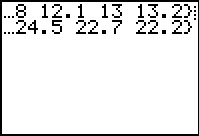 |
| Figure 39 From STAT EDIT 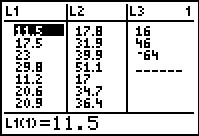 |
Figure 40 From PLOT 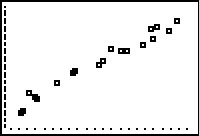 |
Figure 41 From LinReg 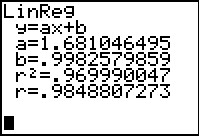 |
| Frequency name | 1 | 2 | 3 | 4 | 5 |
| Relative frequency as a number |
8 | 4 | 5 | 5 | 3 |
| Relative frequency as a percent |
32% | 16% | 20% | 20% | 12% |
# Generate an approximately discrete set of values
# corresponding to given relative frequencies
# this assumes we have loaded pop_sd() into our environment
# this assumes we have loaded gnrnd4() into our environment
gnrnd4( key1=042314207, key2=355485 )
L1 # just to display all the values generated
mean( L1 ) # to find the mean
# to find the standard deviation
sd( L1 ) # if this is a sample
# to find the standard deviation
pop_sd(L1) # if this is a population
summary(L1)# finds lots of values
source("../make_freq_table.R")
make_freq_table( L1 )
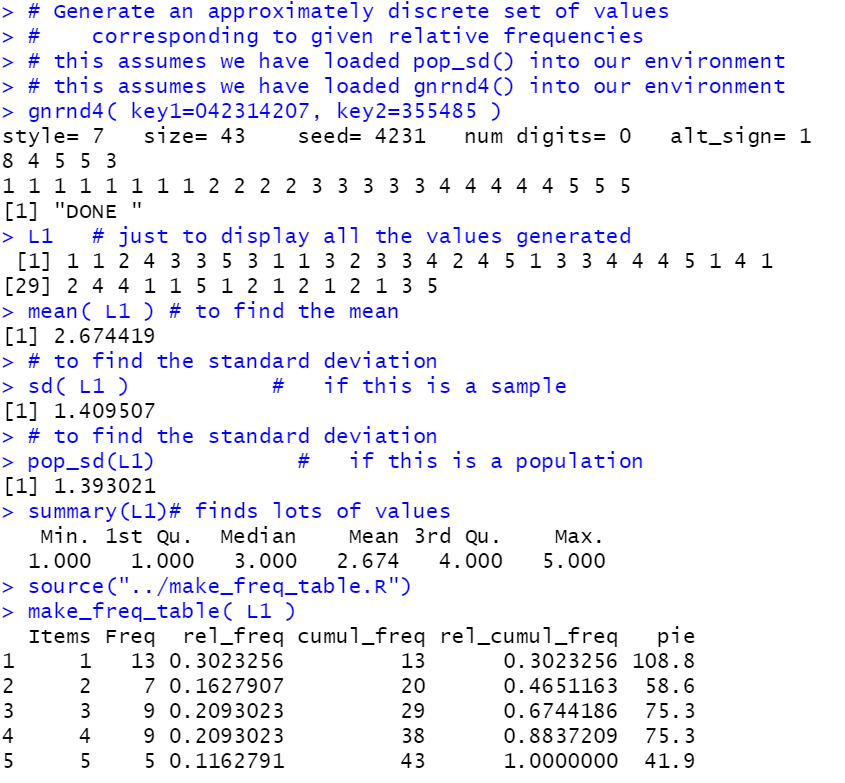
Figure 42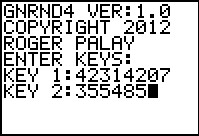 |
Figure 43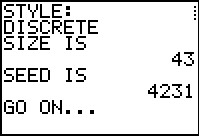 |
Figure 44 |
Figure 45 |
Figure 46 From STAT EDIT 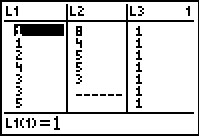 |
Figure 47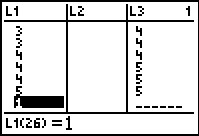 |
| Figure 48 From COLLATE2 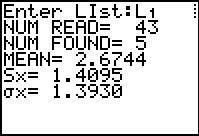 |
Figure 49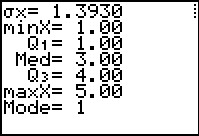 |
Figure 50 From STAT EDIT 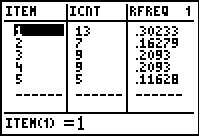 |
| Col Name | 1 | 2 | 3 | 4 | 5 | Row Goal Freq | |
| Row Name | |||||||
| 1 | 7 | ||||||
| 2 | 4 | ||||||
| 3 | 5 | ||||||
| Column Goal Freq. | 4 | 6 | 5 | 7 | 8 |
matrix_A, then display those values.
# Generate a contingency table that has approximate
# row and column distributions
gnrnd4( key1=042310908, key2=8756454753 )
matrix_A # just to display all the values generated
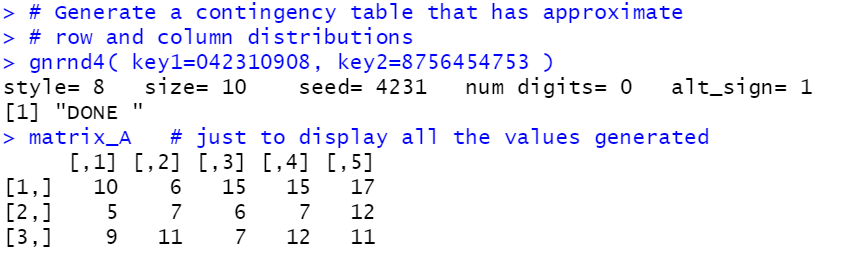
Figure 51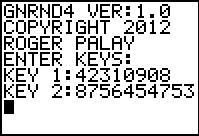 |
Figure 52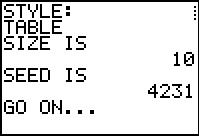 |
Figure 53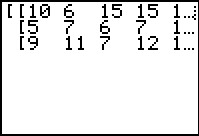 |
Figure 54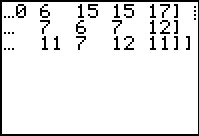 |
| Quartile name | Q1 | Q2 | Q3 | Q4 |
| Percent of range in quartile |
50% | 15% | 25% | 10% |
matrix_A, then display those values.
# Generate a distribution into a specified range such
# that quartiles happen at particular values in that
# range
gnrnd4( key1=042319409, key2=501525300400 )
L1 # just to display all the values generated
#Now look at the quartiles, remembering that R uses a
# different algorithm for calculating the quartiles
# than does the TI-83/84 calculators. Therefore, we
# expect that the results here will be close to but
# not exactly the same as the reported results from
# the TI-83/84 calculators.
summary(L1) # to examine the quartiles

Figure 55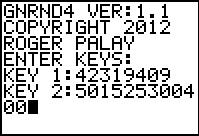 |
Figure 56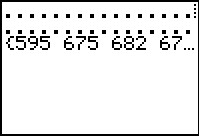 |
Figure 57 |
Figure 58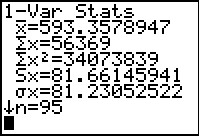 |
Figure 59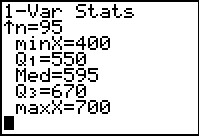 |
Figure 60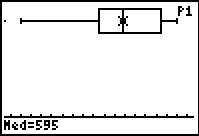 |
L1 and L2, then display those values.
# Generate a normal distribution given mean and standard
# deviation and generate paired values with a given
# the extent of random deviation from the first values.
gnrnd4( key1=1427372510, key2=110008500425 )
L1 # just to display all the x values generated
L1 # just to display all the y values generated
# look at the summary descriptions of both lists
source("../long_summary.R")
long_summary(L1)
long_summary(L2)
# find the differences
L3 <- L1 - L2
L3
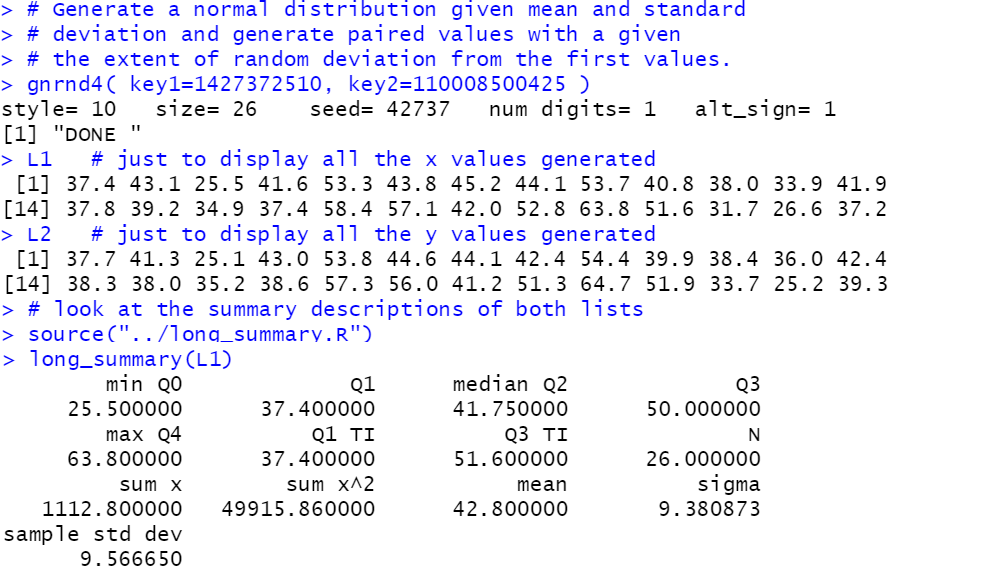

Figure 61 |
Figure 62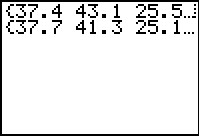 |
Figure 63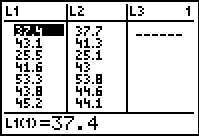 |
Figure 64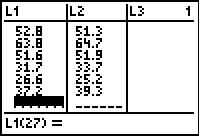 |
Figure 65 From 1-Var Stats for L1 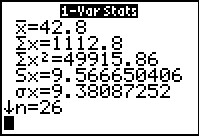 |
Figure 66 From 1-Var Stats for L2 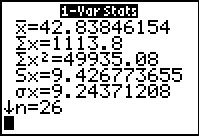 |
Figure 67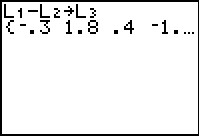 |
Figure 68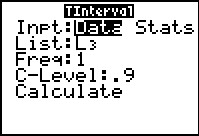 |
Figure 69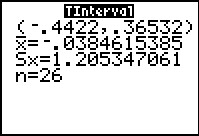 |
This option has not been implemented in the TI-83/84 GNRND4 program.
It only works for the R script gnrnd4().
|
| Col Name | 1 | 2 | 3 | 4 | 5 | Row Goal Freq | |
| Row Name | |||||||
| 1 | 7 | ||||||
| 2 | 4 | ||||||
| 3 | 5 | ||||||
| Column Goal Freq. | 4 | 6 | 5 | 7 | 8 |
matrix_A, then display those values.
# Generate a contingency table that has specific
# row and column distributions but that rejects
# independence at the 0.10 level of significance.
gnrnd4( key1=042313911, key2=8756454753 )
matrix_A # just to display all the values generated
source("../crosstab.R")
crosstab( matrix_A ) # to get the analysis of the matrix
totals # to see all of the row and column totals
# a quick look at the expected values
# for perfect independence
expected
# the chi-squared value, with 8 degrees of freedom,
# that has 10% of the area under the curve to the
# right of this value
qchisq(0.10,8,lower.tail=FALSE)
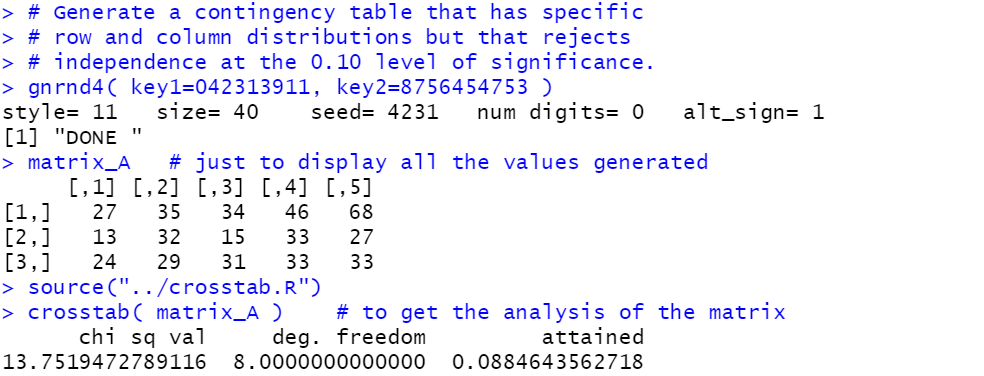
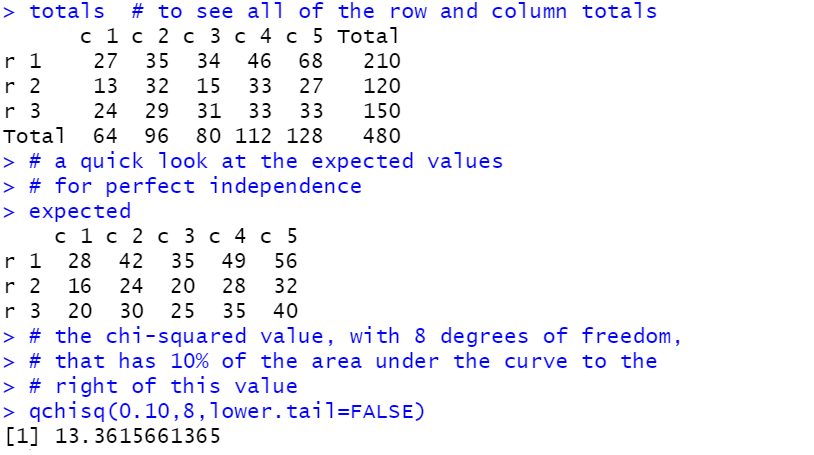
crosstab() function output we can see that
the computed chi-squared value is 13.7519472789116 which is
just slightly larger than the critical value that we
found from the qchisq() function, namely,
13.3615661365, and as a result we would
reject independence at the 0.10 level of significance.
| Key 1 |
d | d d d d d | d d | d d |
| num digits | initial seed value | (generated sample size)-1 | style | |
| Number of decimal digits implied in some second key values and used in generating the actual values in some cases. Also used to determine if certain second key values are negative. Values 0, 1, 2, 3, and 4 represent, respectively 0, 1, 2, 3, or 4 decimal digits. Values 5, 6, 7, 8, 9 represent, respectively, 0, 1, 2, 3, or 4 decimal digits, but with the understanding that some second key values may be negative. | The initial seed value. Generally this is determined by some other random number generator. The value used here then determines the sequence of random values generated by the appropriate functions both in the TI-83/84 program and in the web page. | One less than the desired sample size. Thus a pair of digits such as 11 will generate a 12 item sample, a pair of digits such as 99 will generate a 100 item sample, and a pair of digits such as 00 will generate a 1 item sample. | The style selector. This gives us room for up to 99 different
styles of samples. Initially there are 10 defined styles,
As more styles are specified this list will expand,
Current styles are
|
| Style | Name | Text | |
| 01: | Uniform | A uniform distribution gives an equally likely probability of having each permissible greater than or equal to some specified Low value and a High value determined to be the Low+Range for some specified Range, This is accomplished by taking a uniformly distributed random value between 0 and 1 and applying it to the Range, adding the result to the Low value, and then rounding the result to the specified number of digits. | |
| 02: | Power | This power distribution is identical to the uniform distribution except that the random value that is generated is squared before it is used to scale the Range. The result, since the random values generated initially are between 0 and 1, is to have a distribution that favors low values. | |
| 03: | Root | This power distribution is identical to the uniform distribution except that we take the quare root of the random value that is initially generated before it is used to scale the Range. The result, since the random values generated initially are between 0 and 1, is to have a distribution that favors high values. | |
| Key 2 | d d d d d d | d d d d d | |
| These six digits specify the Range of values that may be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 (which could be specified simply as 100) would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 7. | These five digits represent the Low end of the permisible values to be generated. Note that if the number of digits specied in Key 1 came from a value greater than 4 then this Low values is set to be a negative, Thus, 20000 with the number of decimal digits given as a 6, has an implied decimal value of 200.00, but it is a negative value, that is, -200.00. | ||
| Style | Name | Text | |||||||||
| 04: | Normal | The program generates values that are approximately normally distributed with a specified mean and a specified standard deviation. | |||||||||
| Key 2 | d d d d d | d d d d d | |||||||||
| These five digits specify the goal Standard Deviation of values to be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 (which could be specified simply as 100) would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 7. | These five digits specify the goal Mean of values to be generated. Note that if the number of digits specied in Key 1 came from a value greater than 4 then this Mean values is set to be a negative, Thus, 20000 with the number of decimal digits given as a 6, has an implied decimal value of 200.00, but it is a negative value, that is, -200.00. | ||||||||||
| Style | Name | Text | |||||||||
| 05: | Bi-Modal | The program generateS values that are randomly selected from two approximately normal distributions, each with its own specified mean and standard deviation. Key 2 will give the mean and standard deviation for one distribution, while Key 3 will give the mean and standard deviation for the other distribution. As it generated each value, the process randomly selects which distribution to use. As such, the number of values from each distribution is a random choice and there is no attempt to have an approximately equal number of values from each distribution. | |||||||||
| Key 2 | d d d d d | d d d d d | |||||||||
| These five digits specify the first goal Standard Deviation of values to be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 (which could be specified simply as 100) would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 7. | These five digits specify the first goal Mean of values to be generated. Note that if the number of digits specied in Key 1 came from a value greater than 4 then this Mean values is set to be a negative, Thus, 20000 with the number of decimal digits given as a 6, has an implied decimal value of 200.00, but it is a negative value, that is, -200.00. | ||||||||||
| Key 3 | (-) d d d d d | d d d d d | |||||||||
| These five digits specify the goal Standard Deviation of values to be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 (which could be specified simply as 100) would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 7. The negative sign, if present has no effect on the standard deviation, rather, if there is a leading negative sign then the value of the mean, the last five digits, is made negative. | These five digits specify the second goal Mean of values to be generated. Note that, unlike the first goal mean, this one is turned negative by preceding the specified value with a negative sign. | ||||||||||
| Style | Name | Text | |||||
| 06: | Linear | The linear distribution generates pairs of values, (x,y), such that there is a y=mx+b underlying relationship between the values. To generate our distribution we need to have a Low value for the x-values, a Range for the x-values, a specification for the linear relationship, given as Dy =Mx+B, and an indicator for the maximum amount of error to introduce. The Low and Range values are given in Key 3 while the other valeus are specified in Key 2. | |||||
| Key 2 | d | d | d | d d d | d d | d d | |
| This is a single digit error factor. To calculate the maximum allowed error on any one observation, if E is this digit, find (E+1)(E+2)/200 and apply that to the max change in the model from the Left x value to the Right x value. | This digit indicates the sign of the B value: 0-5=positive; 6-9=negative. | This digit indicates the sign of the M value: 0-5=positive; 6-9=negative. | These three digits give the value of B in Dy=Mx+B, possibly negated from earlier indicator. | These two digits give the value of M in Dy=Mx+B, possibly negated from earlier indicator. | These two digits give the value of D in Dy=Mx+B. | ||
| Key 3 | d d d d d | d d d d d | |||||
| These 5 digits give the Range of the x-values. Note that this value is scaled by the number of decimal digits specified in Key 1. | These 5 digits give the Low value of the x-values. Note that this value is scaled by the number of decimal digits specified in Key 1. In addition, this value may be changed to a negative value based on that same Key 1 value. | ||||||
| Style | Name | Text | |||||||||
| 07: | Discrete | The discrete distribution generates values from 1 to the number of categories in an approximation to the relative frequency given for each of the categories. There should be at least two categories and there can be as many as nine categories. The number of categories and the relative frequencies, as single digits, for each category are given in Key 2. | |||||||||
| Key 2 | d | d | d | d | d | d | d | d | d | d | |
| Relative Freq cat 9 | Relative Freq cat 8 | Relative Freq cat 7 | Relative Freq cat 6 | Relative Freq cat 5 | Relative Freq cat 4 | Relative Freq cat 3 | Relative Freq cat 2 | Relative Freq cat 1 | # of cat | ||
| Style | Name | Text | |||||||||
| 08: | Table |
The Table distribution fills a table with the number of
times a value has been observed in each cell of the table.
This is done with a goal of having a certain relative
frequency in each row and certain relative
frequency in each column of the table.
The second Key gives the number of rows and the number of
columns, along with a relative frequency of each. The specification
below for that second key implies that the sum of the number of rows and number
of columns should not excede eight (8). In fact, it can be 9.
A further note is that the actual number of "observations" is equal to the "size" as given in Key 1 times the number of rows times the number of columns. This is done because having so many cells in a table means that the "observations" are spread out over many cells. Using this factor approach allows us to get much larger values. | |||||||||
| Key 2 | d | d | d | d | d | d | d | d | d | d | |
| Relative Freq col n | Relative Freq col n-1 | Relative Freq col n-2 | Relative Freq | Relative Freq | Relative Freq | Relative Freq row 2 | Relative Freq row 1 | # of cols | # of rows | ||
| As implied above, these 8 digits hold the relative frequencies of the rows and columns. Reading right to left we find the relative frequency of row 1, row 2, and so on until we are done with the row values. Then we start with the column relative frequencies. Since there are but 8 digits in this group, we want the number of rows plus the number of columns to be no more than 8. The actual limit is 9, but the documentation here is a bit easier if we show only 8. | |||||||||||
| Style | Name | Text | |||||
| 09: | Quartile | The Quartile Points distribution chooses random values from the Low value to the Low+Range value such that we have Quartile points set at a specified percent across the range of values. Thus, we could have a range of 300 and specify quartile widths (i.e., the span) at 50%, 15%, 25%, and 10%. These correspond to a span of 150, 45, 75, and 30. The range of values is divided accordingly. Quartile points are set, remaining values are allocated. The values are placed in the list in random order. Also, If the IQR is such that 1.5*IQR does not cover the first or fourth quartile, then the program ensures that there is one point in the outlier region. Finally, the specified size for the sample is always rounded up to one less than the next multiple of 4. | |||||
| Key 2 | pp | pp | pp | d d d | d d d | ||
| This is the percent of the range given to the first quartile. | This is the percent of the range given to the second quartile. | This is the percent of the range given to the third quartile. Note that the fourth quartile gets the remaining part of the range. | These three digits give the range, possibly altered by the number of decimal digits. | These three digits give the low value, possibly altered by the number of decimal digits. | |||
| Style | Name | Text | |||
| 10: | Paired Normal | The program generates values that are approximately normally distributed with a specified mean and a specified standard deviation. In addition, the program generates a second list with values paired to the first list. | |||
| Key 2 | d d | d d d d d | d d d d d | ||
| These two digits specify the spread of the paired values. In particular, values near 00 produce almost no spread while values near 99 produce a great spread and one that is shifted to have the second value tending to be greater than the first. | These five digits specify the goal Standard Deviation of values to be generated. Note that the number of decimal digits specified in Key 1 places an implied decimal point within the specified digits. Thus, the value 000100 (which could be specified simply as 100) would mean, 100 if the number of decimal digits in Key 1 is 0 or 5. On the other hand, 100 would mean 0.100 if the number of decimal digits in Key 1 is 3 or 7. | These five digits specify the goal Mean of values to be generated. Note that if the number of digits specied in Key 1 came from a value greater than 4 then this Mean values is set to be a negative, Thus, 20000 with the number of decimal digits given as a 6, has an implied decimal value of 200.00, but it is a negative value, that is, -200.00. | |||
| Style | Name | Text | |||||||||
| 11: | Independence |
The Independence distribution fills a table with the number of
times a value has been observed in each cell of the table.
This is done with a goal of having a certain relative
frequency in each row and certain relative
frequency in each column of the table.
Furthermore, the table is changed from prefectly independent to failing
the test for independence at a given level of significance.
The second Key gives the number of rows and the number of
columns, along with a relative frequency of each. The specification
below for that second key implies that the sum of the number of rows and number
of columns should not excede eight (8). In fact, it can be 9.
A further note is that the expected number of "observations" is determined by the expected values, which are just the product of the row expected proportion and the column expected proportion. However, a multiplier is used to be sure that the lowest expected value is more than 10. A further aberation is that we determine the goal significance level at which the resuting table will just fail a chi-squared test for independence. That goal level is computed as the first key generated sample size
divided by 400. Thus the two digit sample size 99 produces a desired sample
size of 100 and thus a goal value of 100/400=25%, and the two digit sample size 09 produces a
desired sample size of 10 and thus a goal value of 10/400=2.5%.
| |||||||||
| Key 2 | d | d | d | d | d | d | d | d | d | d | |
| Relative Freq col n | Relative Freq col n-1 | Relative Freq col n-2 | Relative Freq | Relative Freq | Relative Freq | Relative Freq row 2 | Relative Freq row 1 | # of cols | # of rows | ||
| As implied above, these 8 digits hold the relative frequencies of the rows and columns. Reading right to left we find the relative frequency of row 1, row 2, and so on until we are done with the row values. Then we start with the column relative frequencies. Since there are but 8 digits in this group, we want the number of rows plus the number of columns to be no more than 8. The actual limit is 9, but the documentation here is a bit easier if we show only 8. | |||||||||||